
記憶體階層進階:用 I/O 模型推導逼近硬體極限的演算法
從外部記憶體模型、分塊與 cache-oblivious,到 write policy、記憶體牆與 NUMA——把快取行為從直覺升級成可量化的計算理論
當「演算法複雜度相同」卻差了一百倍:我們需要一個新的計算模型
你已經知道記憶體階層是一座「越近越快越小」的金字塔,也知道命中率主宰了平均存取時間(AMAT)。但這裡有一個更尖銳的問題:如果兩個演算法的時間複雜度都是 $O(n^3)$,加減乘除的次數一模一樣,為什麼其中一個可以快上百倍?
入門篇的答案是「區域性比較好」。可是這個答案太模糊了——好在哪裡?好多少?能不能在動手寫程式之前,就用紙筆「算」出哪個版本的快取行為更好?這正是進階篇要回答的:我們要把記憶體階層從「直覺」升級成「可量化的計算模型」,並用它推導出能逼近硬體極限的演算法。當你能用一條公式預測快取失誤的數量,你對效能的掌握就從碰運氣變成了工程。
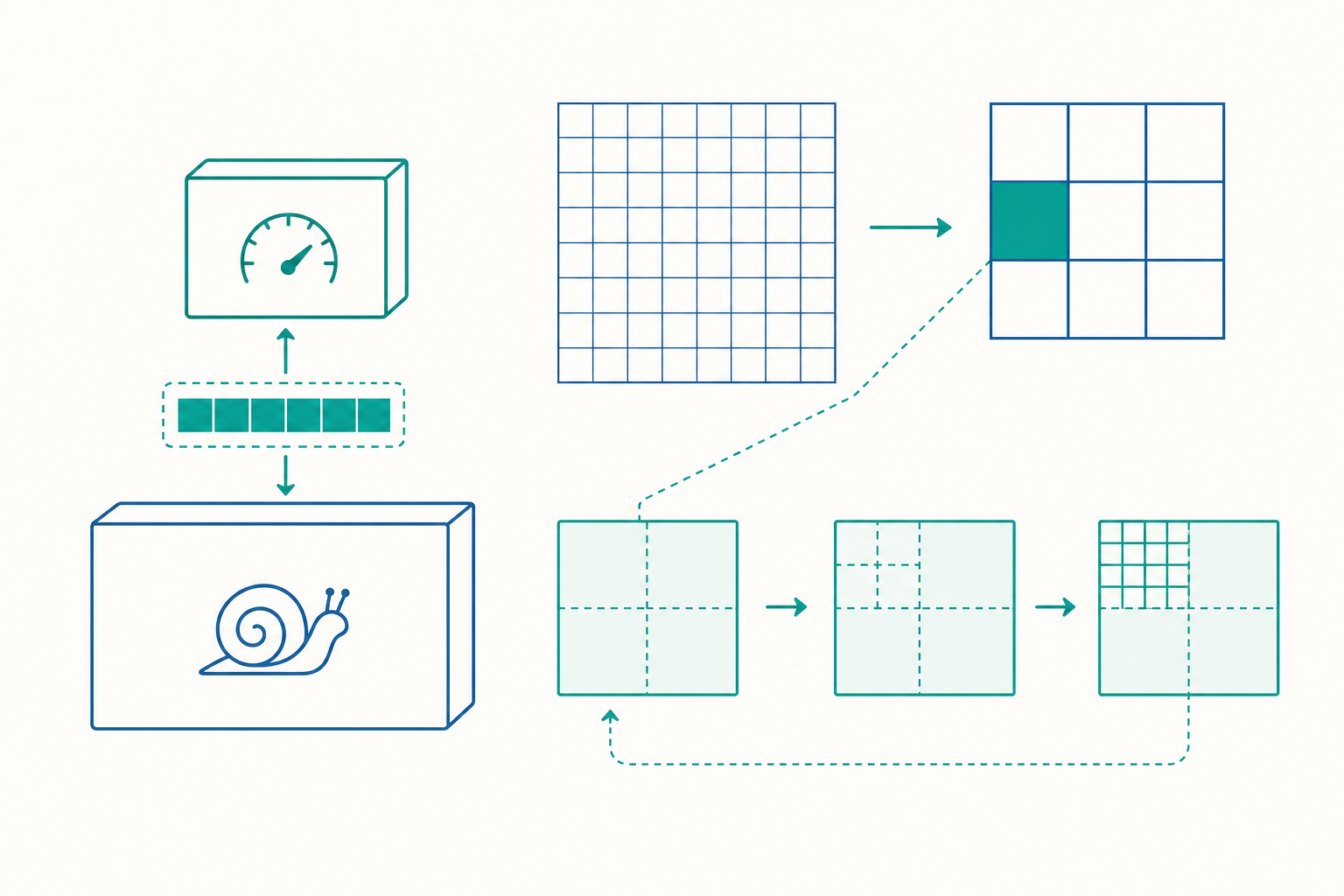
外部記憶體模型:把「搬運成本」放進複雜度
傳統演算法分析用的是 RAM 模型(Random Access Machine):假設每一次記憶體存取都花同樣的、常數的時間。這個假設在 1970 年代還算合理,但在今天,一次 L1 快取命中與一次主記憶體存取相差約一百倍——把它們當成等成本,等於閉著眼睛分析效能。
於是計算機科學家提出了 外部記憶體模型(External Memory Model),又稱 I/O 模型 或 快取感知模型(cache-aware model)。它把系統簡化成兩層:一層「快」的記憶體,容量為 $M$ 個字組;一層「慢」的記憶體,容量無限。資料在兩層之間,一定是以大小為 $B$ 的區塊(block)為單位整批搬運——這正對應到快取列(cache line)或磁碟頁(page)。
在這個模型裡,我們不再數「執行了幾個指令」,而是數 I/O 次數:總共觸發了多少次「從慢層搬一個區塊到快層」。一個演算法的 I/O 複雜度 才是真正預測它在記憶體階層上跑多快的量。
舉個立刻見效的例子。循序掃過一個含 $n$ 個元素的陣列:
慢層:[ □ □ □ □ □ □ □ □ □ □ □ □ ... ] (n 個元素)
搬運:每次帶回 B 個 → 只需 n/B 次 I/O
因為空間區域性,每搬一個區塊就能用掉 $B$ 個元素,總 I/O 數是 $O(n/B)$——掃描 $n$ 個元素,I/O 卻被 $B$ 除掉了。對照之下,若你以隨機順序存取這 $n$ 個元素,幾乎每次都打到新區塊,I/O 數是 $O(n)$。在 RAM 模型裡這兩者都是 $O(n)$,看不出差別;在 I/O 模型裡,差距是 $B$ 倍——而 $B$ 對 64 位元組的快取列、4 位元組的整數而言正好是 16,對 4 KB 的磁碟頁更可達上千。入門篇觀察到的「列走訪 vs 欄走訪」差數倍,在這裡有了精確的名字與量級。
分塊(tiling):用 I/O 模型推導矩陣乘法
光會分析還不夠,I/O 模型真正的價值是能指導我們設計演算法。最經典的案例是矩陣相乘 $C = A \times B$,三個矩陣皆為 $n \times n$。
動手算一下:天真版本的 I/O 災難
教科書的三層迴圈是這樣:
for (int i = 0; i < n; i++)
for (int j = 0; j < n; j++)
for (int k = 0; k < n; k++)
C[i][j] += A[i][k] * B[k][j];
計算量是 $O(n^3)$,這沒得改。問題出在 B[k][j]:最內層迴圈固定 j、變動 k,意味著我們沿著矩陣 B 的一整欄往下走。在列主序儲存下,B[k][j] 與 B[k+1][j] 在記憶體中相隔 $n$ 個元素,每次存取幾乎都跳到新的快取列。
假設快取總共裝不下一整列(即 $n$ 大到 $M < n$),那麼:
- 計算 $C$ 的每一個元素都要掃過
A的一列與B的一欄,共 $2n$ 次存取,其中對B的存取幾乎每次都失誤。 - 整個 $C$ 有 $n^2$ 個元素,總 I/O 數約為 $O(n^3)$——沒有任何區塊被重複利用,搬進來算一次就被擠掉。
I/O 複雜度 $O(n^3)$ 與計算複雜度同階,代表這個程式是記憶體頻寬綁住(memory-bound)的:CPU 大半時間在等資料,而不是在算乘法。
分塊版本:讓資料「進來就用好用滿」
關鍵洞見是:既然搬一塊資料進快取很貴,就要在它被擠出去之前榨乾它的價值。做法是把矩陣切成 $b \times b$ 的小方塊(tile / block),讓三個小方塊能同時塞進快取(即 $3b^2 \le M$),在小方塊內完成所有乘加後,再換下一塊。
for (int ii = 0; ii < n; ii += b)
for (int jj = 0; jj < n; jj += b)
for (int kk = 0; kk < n; kk += b)
// 此刻 A、B、C 的 b×b 子塊都常駐快取
for (int i = ii; i < ii + b; i++)
for (int j = jj; j < jj + b; j++)
for (int k = kk; k < kk + b; k++)
C[i][j] += A[i][k] * B[k][j];
來數 I/O。每搬入一組 $b \times b$ 子塊,花 $O(b^2/B)$ 次 I/O,卻能完成 $b^3$ 次乘加。整個矩陣被切成 $(n/b)^3$ 組子塊計算,總 I/O 數為:
$$\text{I/O} = \left(\frac{n}{b}\right)^3 \times O\!\left(\frac{b^2}{B}\right) = O\!\left(\frac{n^3}{b \cdot B}\right)$$
把 $b$ 取到快取能容納的最大值,即 $b \approx \sqrt{M}$,得到:
$$\text{I/O} = O\!\left(\frac{n^3}{B\sqrt{M}}\right)$$
對照天真版的 $O(n^3)$,分塊版省下了 $B\sqrt{M}$ 倍的 I/O。這個 $O(n^3 / (B\sqrt{M}))$ 不是隨便湊的——Hong 與 Kung 在 1981 年證明它就是矩陣乘法 I/O 複雜度的理論下界,意思是沒有任何標準矩陣乘法演算法能比它再省一個數量級。分塊版本已經摸到了硬體的天花板,這就是 BLAS、NumPy、PyTorch 底層線性代數庫都採用分塊的原因。
不知道 $M$ 與 $B$ 也能最佳:cache-oblivious 演算法
分塊版有個現實上的麻煩:你必須知道快取多大($M$)才能挑對 $b$。但現實機器有 L1、L2、L3 三層快取,每層 $M$ 與 $B$ 都不同;換一台機器、換一個世代,最佳的 $b$ 就變了。難道每換硬體就要重新調參數?
cache-oblivious 演算法(快取無關演算法,Frigo 等人於 1999 年提出)給了一個漂亮的答案:用遞迴分治自動產生所有尺度的區塊,程式碼裡完全不出現 $M$ 或 $B$,卻能在每一層快取同時達到(漸進意義上的)最佳 I/O。
以矩陣乘法為例,把矩陣對半切,遞迴地做八個半尺寸的子乘法:
[A11 A12] [B11 B12] [A11·B11+A12·B21 A11·B12+A12·B22]
[A21 A22] [B21 B22] = [A21·B11+A22·B21 A21·B12+A22·B22]
void matmul(M_A, M_B, M_C, n) {
if (n <= THRESHOLD) { base_case(); return; } // 小到塞進快取就直接算
切成四塊,遞迴呼叫 8 次半尺寸 matmul,並累加
}
它的妙處在於:遞迴下降時,子問題的尺寸連續地、自動地變小。當某一層遞迴的子矩陣恰好小到能塞進 L3,它對 L3 就是「分塊」的;再往下一兩層恰好塞進 L2、L1,又分別對 L2、L1 是「分塊」的。程式不需要知道任何一層的容量,分治結構替它在所有尺度上都做對了事。可以證明它的 I/O 複雜度同樣是 $O(n^3 / (B\sqrt{M}))$——與需要手動調參的快取感知版本漸進相同。
這帶來一個深刻的觀念轉變:好的遞迴結構本身就是一種跨層級的區域性。merge sort、快速傅立葉轉換(FFT)、van Emde Boas 樹佈局等,都有對應的 cache-oblivious 版本。當然,cache-oblivious 通常會輸給針對特定硬體手工調校到極致的 cache-aware 版本一個常數因子,但它「一份程式碼,跨硬體都接近最佳」的可攜性,在實務上極具吸引力。
寫入怎麼辦:write policy 與被忽略的另一半
到目前為止(以及入門篇)談的多半是「讀」。但程式也會寫資料,而寫入在快取裡是一套獨立、常被忽略的機制,會實際影響你的程式效能。
當 CPU 要寫入某位址,有兩個正交的決策:
1. 命中時怎麼同步到下層?
- 寫穿(write-through):每次寫入同時更新快取與下層記憶體。實作簡單、下層永遠是最新的,但每次寫都要付出慢層的頻寬。
- 寫回(write-back):只先寫快取,把該快取列標記為「髒(dirty)」,等到它要被置換時才一次寫回下層。大幅減少寫入流量,是現代 CPU 的主流,代價是邏輯較複雜、需要追蹤髒位元。
2. 寫入失誤時要不要先把資料載入快取?
- 寫配置(write-allocate):寫入失誤時,先把整個快取列載進來再寫。通常與寫回搭配,因為接下來很可能還會寫到同一列。
- 非寫配置(no-write-allocate):失誤就直接寫到下層,不污染快取。通常與寫穿搭配。
這對寫程式有實際意義。例如你初始化一個大到遠超快取的陣列 memset(buf, 0, huge):在 write-allocate 策略下,每寫一個新快取列前都要先把它的「舊內容」從記憶體讀進來,但你根本不在乎舊值——這是純粹的浪費。這也是為什麼 x86 提供 非暫時性寫入(non-temporal store) 指令(如 movnti),讓你繞過快取、直接串流寫入記憶體,避免無謂的讀取與快取污染。當你處理的是「寫了就不會再讀」的大量資料時,這個技巧能省下一半的記憶體頻寬。
記憶體牆、頻寬與 MLP:延遲不是唯一的故事
入門篇的 AMAT 公式專注於延遲(latency)——單次存取要等多久。但現代效能還有另一條軸線:頻寬(bandwidth)——單位時間能搬多少資料。兩者並不等價,混淆它們會導致錯誤的最佳化方向。
過去數十年,CPU 速度成長遠快於記憶體速度,兩者差距持續擴大,這個現象稱為 記憶體牆(memory wall)。處理器架構師的對策不是讓記憶體變快(物理上很難),而是想辦法同時處理很多筆未完成的存取,用平行度掩蓋延遲。這裡有一條來自排隊理論的關鍵關係,Little's Law:
$$\text{有效頻寬} = \frac{\text{同時在途的請求數}}{\text{平均延遲}}$$
換句話說,即使單筆存取的延遲固定(比如 100 ns),只要你能讓記憶體系統「同時」處理夠多筆獨立的存取,整體吞吐量就能上去。這個「同時在途的獨立記憶體存取數」稱為 記憶體層級平行度(Memory-Level Parallelism, MLP)。現代 CPU 用亂序執行(out-of-order)、非阻塞快取(non-blocking cache)、以及 硬體預取器(hardware prefetcher)——偵測到你在規律地循序存取,就提前把後面的快取列抓進來——來榨出 MLP。
這解釋了一個對寫程式很重要的現象:指標追逐(pointer chasing) 為什麼這麼慢。走訪鏈結串列(linked list)時,node = node->next,下一個要存取的位址,必須等這一個 cache miss 回來才知道——這是一串相依的存取,MLP 退化成 1,每筆 100 ns 延遲赤裸裸地累加。反之,走訪陣列時各元素位址彼此獨立,CPU 可以同時發出許多筆存取、又有預取器助攻,把延遲藏起來。這也是為什麼在大量隨機查找的場景,「對快取友善的開放定址雜湊表」常勝過「節點四散的鏈結結構」——即使兩者大 O 相同。
NUMA:當「主記憶體」本身也分了遠近
最後一個進階面向:在多插槽伺服器與現代多核晶片上,連「主記憶體」都不再是均質的。NUMA(Non-Uniform Memory Access,非均勻記憶體存取) 架構下,每顆 CPU(或每個晶片小區塊)有自己「本地」的一塊 DRAM,存取本地記憶體快,存取「別人的」記憶體要經過互連匯流排,慢上一截。
於是記憶體階層在 DRAM 這一層又長出了「近 DRAM」與「遠 DRAM」的細分。這對高效能與資料庫程式有實際影響:作業系統的 first-touch 配置策略 會把一塊記憶體實際分配到「第一個寫入它的執行緒所在的節點」。如果你在主執行緒一次初始化完所有資料、再分給各執行緒平行處理,所有資料可能都擠在一個節點上,其他核心全在做遠端存取——一個經典的反效能模式。正確做法是讓每個執行緒各自初始化自己稍後要用的那塊資料,讓 first-touch 把資料就近放好。
NUMA 再次印證了本文的核心訊息:記憶體階層是一個遞迴、處處出現的母題。從暫存器到 L1、L2、L3,到本地 DRAM、遠端 DRAM,到 SSD、到網路儲存——每一層都在重演「近而快而小、遠而慢而大」的同一齣戲,而「想辦法提升區域性、增加平行度、攤平搬運成本」永遠是不變的解法。
重點回顧
- 外部記憶體(I/O)模型 用兩層記憶體 $(M, B)$ 與「I/O 次數」取代等成本的 RAM 模型,讓快取行為變成可推導、可量化的複雜度,而非模糊的直覺。
- 分塊(tiling) 把資料切成能塞進快取的子塊重複利用,將矩陣乘法的 I/O 從 $O(n^3)$ 降到 $O(n^3/(B\sqrt{M}))$——這正是 Hong–Kung 證明的理論下界,也是 BLAS/NumPy 的核心技巧。
- cache-oblivious 演算法 用遞迴分治在所有快取層級同時達到漸進最佳 I/O,程式碼不需知道 $M$ 與 $B$,換來跨硬體的可攜性。
- 寫入有獨立的 write policy(寫回/寫穿、寫配置/非寫配置);理解它才能用 non-temporal store 等技巧避免無謂頻寬浪費。
- 效能有延遲與頻寬兩條軸;現代 CPU 靠 MLP、亂序執行與硬體預取掩蓋延遲,因此相依的指標追逐遠慢於獨立的陣列走訪。NUMA 則讓「主記憶體」本身也分遠近。
深入探討(研究所視角)
把記憶體階層當成計算模型來研究,是演算法工程(algorithm engineering)與計算機架構交會的活躍領域。Hong–Kung 的紅藍鵝卵石賽局(red-blue pebble game) 提供了證明 I/O 下界的通用框架:它把計算抽象成有向無環圖(DAG)上的鵝卵石移動,藍石代表慢層、紅石代表只有 $M$ 顆的快層,任何計算排程都對應一種放石策略,而最少的「重新放藍石」次數就是 I/O 下界。矩陣乘法的 $\Omega(n^3/\sqrt{M})$ 即由此得出。值得一提的是,Strassen 的 $O(n^{2.807})$ 演算法有不同(更低)的 I/O 下界,顯示計算複雜度與 I/O 複雜度可以解耦——這是研究所層級常被忽略的精妙之處。
第二個延伸是理論模型與真實硬體的落差。理想化的兩層 I/O 模型假設區塊邊界對齊、置換為最佳(Bélády)、且只有兩層;真實快取是多層、組關聯有限、置換是近似 LRU、還有 TLB 與虛擬記憶體頁的雙重分塊。因此學界發展了多層快取的 cache-oblivious 分析、以及考量 TLB miss 的模型。一個實務上的痛點是「快取抖動(cache thrashing)」與「false sharing」:在多核並行下,兩個執行緒各自寫入同一條快取列上的不同位元組,會因快取一致性協定(MESI)反覆使對方的副本失效,造成明明沒有資料相依、效能卻崩潰的詭異現象——解法是把熱點變數對齊並墊到不同快取列(padding to cache-line size)。
第三,Roofline 模型 把上述延遲/頻寬/計算的權衡統整成一張圖。它以「運算強度(arithmetic intensity)」——每搬一位元組資料做幾次浮點運算——為橫軸,以可達效能為縱軸,畫出一條由記憶體頻寬決定的斜線屋頂與由峰值算力決定的水平屋頂。一個 kernel 落在斜線下方代表它是 memory-bound(該想辦法提升區域性與運算強度),落在水平段下方則是 compute-bound。本文的分塊技巧,本質上就是在提高運算強度——讓每搬一塊資料能做更多計算,把程式從頻寬屋頂往算力屋頂推。對研究 GPU、HPC 與深度學習 kernel 最佳化的人而言,Roofline 是日常工具,而它的根,正是這篇文章一路談來的:記憶體階層上,資料的搬運成本,才是效能真正的主戰場。