
記憶體管理進階:分頁表、配置器與垃圾回收的真實成本
同一個程式「用了多少記憶體」為何沒有單一答案?穿過多級分頁表、TLB、使用者空間配置器、COW 與 GC 的層層機制,看清記憶體如何被計價、共享與回收。
當你的程式「沒在用的記憶體」其實一直在花錢
在入門篇裡,你已經知道作業系統會把虛擬位址(virtual address)切成頁(page),透過分頁表(page table)對應到實體記憶體(physical memory),缺頁時觸發 page fault 再從磁碟搬進來。這套機制看起來很完整——但它隱藏了一個讓無數工程師踩雷的真相:
你的程式「用了多少記憶體」這句話,根本沒有單一答案。
同一個行程(process),用 ps 看到 2 GB,用工作管理員看到 800 MB,用 malloc 統計只配置了 300 MB,而真正「獨佔」的實體頁可能只有 120 MB。這些數字全部正確,只是衡量的東西不同。進階篇要帶你穿過這層迷霧:我們會拆解多級分頁表(multi-level page table)與 TLB 的真實成本、剖析使用者空間配置器(user-space allocator)如何在 OS 之上再蓋一層、釐清 RSS/PSS/commit 這些常被混為一談的指標,最後進到垃圾回收(garbage collection)與寫時複製(copy-on-write)的底層機制。
如果說入門篇回答「記憶體怎麼對應」,進階篇回答的是「記憶體怎麼被計價、被共享、被回收」。
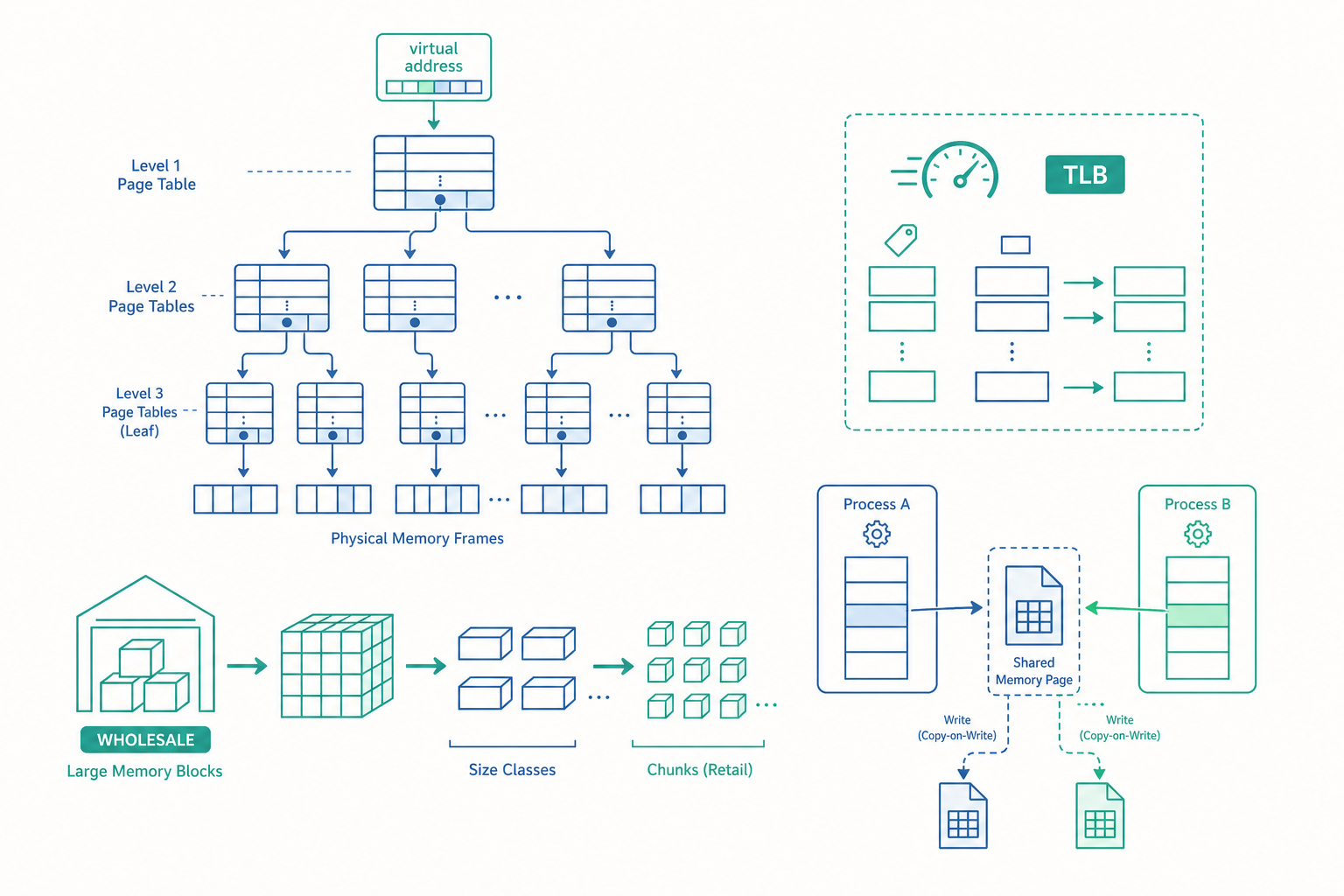
多級分頁表:為什麼不能用一張大表
入門篇通常把分頁表畫成「一張查找表」。但讓我們算一下這張表如果真的攤平會多大。
假設 64 位元系統實際使用 48 位元虛擬位址,頁大小 4 KB(即 $2^{12}$ bytes)。那麼頁的數量是 $2^{48} / 2^{12} = 2^{36}$ 個。每個分頁表項(page table entry, PTE)8 bytes,攤平的單層表就要:
$$2^{36} \times 8 \text{ bytes} = 2^{39} \text{ bytes} = 512 \text{ GB}$$
每一個行程都要 512 GB 的表——這顯然荒謬。而且絕大多數行程只用到位址空間裡極小的一塊(程式碼、堆疊、堆積各佔幾個區段),這張巨表 99.99% 是空的。
解法是多級分頁表:把虛擬位址切成數段,逐層索引,只為「真的有用到」的子樹配置下層表。x86-64 用 4 級(PML4 → PDPT → PD → PT),位址欄位長這樣:
位元 47 39 38 30 29 21 20 12 11 0
┌───────────┬──────────┬──────────┬──────────┬───────────┐
│ PML4 idx │ PDPT idx │ PD idx │ PT idx │ page offset│
│ 9 bits │ 9 bits │ 9 bits │ 9 bits │ 12 bits │
└───────────┴──────────┴──────────┴──────────┴───────────┘
每級用 9 個位元索引一張 512 項($2^9$)的表,每張表剛好 4 KB(512 × 8 bytes),自己就是一個頁。一次位址轉換要走 4 次記憶體查找——這正是 TLB 存在的理由。
動手算一下:稀疏配置省下多少
假設一個行程只用了 4 個頁(程式碼 1 頁、資料 1 頁、堆積 1 頁、堆疊 1 頁),且它們的虛擬位址恰好分散在四個不同的 PML4 子樹。在最壞情況下需要的表數量是:
# 每用到一個分散的頁,最壞情況需要 4 級各一張表
levels = 4
table_size = 4096 # 每張表 4 KB
pages_used = 4
# 最壞:每個頁各自獨佔一條從根到葉的路徑(但共用根 PML4)
worst_tables = 1 + pages_used * (levels - 1) # 1 張 PML4 + 每頁 3 張下層
overhead = worst_tables * table_size
print(f"分頁表開銷上界:{worst_tables} 張表 = {overhead/1024:.0f} KB")
# 分頁表開銷上界:13 張表 = 52 KB
從 512 GB 降到數十 KB。代價是查找變慢(4 次記憶體存取),這個代價由 TLB 來吸收。
TLB:被忽略的效能瓶頸
TLB(Translation Lookaside Buffer)是 MMU 內的小型快取,存「虛擬頁號 → 實體頁框」的對應。命中時轉換幾乎零成本;未命中(TLB miss)就得走完整的 page table walk。
關鍵數字感受一下:典型 L1 TLB 只有 64~128 個項,每項覆蓋 4 KB,也就是只能即時覆蓋約 256 KB~512 KB 的位址範圍。一旦你的工作集(working set)跳出這個範圍且存取模式分散,TLB miss 會主宰效能。
看一個例子:列優先 vs 欄優先的 TLB 災難
#define N 4096
double a[N][N]; // 連續配置,每列 N*8 = 32 KB
// 版本 A:列優先(row-major),記憶體連續存取
for (int i = 0; i < N; i++)
for (int j = 0; j < N; j++)
a[i][j] += 1.0;
// 版本 B:欄優先(column-major),每次跨 32 KB
for (int j = 0; j < N; j++)
for (int i = 0; i < N; i++)
a[i][j] += 1.0;
兩個版本做的事完全相同,記憶體量也相同。但版本 B 每存取一個元素就跳一整列(32 KB)——遠超一個頁,幾乎每次都 TLB miss 也 cache miss。實測下版本 B 常慢 5~10 倍。
緩解手段是大頁(huge page)。把頁從 4 KB 換成 2 MB,單一 TLB 項覆蓋範圍擴大 512 倍:
# Linux 顯式大頁(一次配置 512 個 2MB 大頁 = 1 GB)
echo 512 > /sys/kernel/mm/hugepages/hugepages-2048kB/nr_hugepages
# 或讓核心透明地嘗試合併(Transparent Huge Pages)
cat /sys/kernel/mm/transparent_hugepage/enabled
# [always] madvise never
代價:大頁無法被分頁出去(不可 swap)、可能造成記憶體浪費(內部碎片)、且 THP 的背景合併可能引入延遲尖峰,對延遲敏感的系統(如交易引擎、即時資料庫)反而常選擇關閉 THP。
使用者空間配置器:OS 之上的第二層
這裡是入門篇通常略過、但實務最關鍵的一層。當你呼叫 malloc(24),作業系統完全不知道這件事。OS 只認頁(4 KB 為單位),它不可能為了 24 bytes 給你一個系統呼叫。
真相是:malloc 是 C 函式庫裡的使用者空間配置器(如 glibc 的 ptmalloc、Google 的 tcmalloc、FreeBSD 的 jemalloc)。它向 OS 批發大塊記憶體(透過 brk/sbrk 推高堆積邊界,或 mmap 映射匿名區段),然後在這塊大記憶體裡零售小區塊給你。
你的程式 配置器 作業系統
┌──────────────┐ ┌──────────────┐ ┌──────────────┐
│ malloc(24) │─────▶│ 從 size-class │ │ │
│ malloc(40) │ │ 的 free list │ │ brk / mmap │
│ free(p) │ │ 切一塊給你 │◀───│ 批發整頁區段 │
└──────────────┘ │ 不夠才找 OS │ │ (4KB 為單位)│
└──────────────┘ └──────────────┘
零售(bytes) 中間商(size class) 批發(pages)
這層設計解釋了三件常讓初學者困惑的事:
free後記憶體常不還給 OS。 配置器把釋放的區塊放回自己的 free list 等下次重用,因為brk只能線性增減、munmap也有成本。所以你free了大量物件,作業系統看到的 RSS 卻沒降。- 配置不是 $O(1)$ 也不是無碎片。 現代配置器把請求按大小分到不同的 size class(如 8, 16, 32, 48… bytes),每類維護獨立的 free list。
malloc(24)實際給你 32 bytes——多出的 8 bytes 是內部碎片(internal fragmentation)。 - 多執行緒下有 arena。 ptmalloc 為每個執行緒分配獨立的 arena 以減少鎖競爭,這也是為什麼多執行緒程式的記憶體用量常比預期高。
動手算一下:內部碎片的真實成本
# 模擬 size-class 對齊造成的內部碎片
size_classes = [8, 16, 32, 48, 64, 80, 96, 112, 128]
def round_up(req):
for c in size_classes:
if req <= c:
return c
return ((req + 15) // 16) * 16 # 大於 128 後以 16 對齊
requests = [24, 40, 1, 65, 100, 7, 33]
total_req = sum(requests)
total_alloc = sum(round_up(r) for r in requests)
waste = total_alloc - total_req
print(f"請求 {total_req} bytes,實配 {total_alloc} bytes,"
f"內部碎片 {waste} bytes({waste/total_alloc:.1%})")
# 請求 270 bytes,實配 336 bytes,內部碎片 66 bytes(19.6%)
近 20% 的浪費並不罕見。這是「速度 vs 空間」的經典取捨:對齊到 size class 讓配置/釋放變成 free list 的 $O(1)$ 推入彈出,代價是空間浪費。
RSS、PSS、Commit:到底用了多少記憶體
現在我們有能力回答開頭的謎題了。不同工具量的是不同層次:
| 指標 | 全名 | 量的是什麼 |
|---|---|---|
| VSZ / VIRT | Virtual Size | 行程虛擬位址空間總大小(包含從未碰過的保留區) |
| RSS | Resident Set Size | 此刻在實體記憶體的頁,但共享頁重複計算 |
| PSS | Proportional Set Size | 共享頁按分攤計(被 $N$ 個行程共享就算 $1/N$) |
| Commit | Committed memory | 系統承諾可提供的量(影響 OOM 與是否能 mmap) |
關鍵洞見:VSZ 幾乎沒意義(你 mmap 一個 1 GB 檔案但只讀第一頁,VSZ 就 +1 GB),RSS 會高估共享(10 個行程共用 glibc,每個 RSS 都算進那份函式庫),PSS 才是「公平分攤」的真實佔用。
# 看一個行程各記憶體區段的 RSS 與 PSS 細分
cat /proc/<pid>/smaps_rollup
# Rss: 812345 kB
# Pss: 520118 kB ← 扣掉共享分攤後的真實佔用
# Shared_Clean: 180000 kB ← 與他人共享、未修改(如函式庫程式碼)
# Private_Dirty: 410000 kB ← 只有你改過、無法共享,最「貴」
Private_Dirty 是最該盯的數字——它是這個行程獨佔、且因為被修改而不能與任何人共享、也不能單純丟棄的頁。要降低記憶體壓力,就是要降這個。
Overcommit:作業系統的超賣策略
Linux 預設超賣(overcommit)記憶體:malloc 成功不代表實體記憶體真的存在,只是回了一段虛擬位址。實體頁要等你真的寫入時才透過 page fault 配置(demand paging)。
// 在預設 overcommit 下,這行可能「成功」即使你沒有 100 GB RAM
char *huge = malloc(100L * 1024 * 1024 * 1024);
if (huge) {
huge[0] = 'A'; // 只有這一頁真的被配置
// 若真的逐頁寫滿,OOM Killer 才會被觸發殺掉某個行程
}
這就是為什麼「malloc 回傳非 NULL」不等於「記憶體可用」,也是 fork 一個大行程卻沒立刻爆掉的原因——它依賴下一個主題。
寫時複製:fork 的魔法
當你 fork() 一個 4 GB 的行程,作業系統不會複製 4 GB。它讓父子行程的分頁表都指向同一批實體頁,並把這些頁全部標記為唯讀。只有當任一方寫入某頁時,才觸發保護錯誤(protection fault),核心此時才真的複製那一頁——這就是寫時複製(copy-on-write, COW)。
fork 之後(尚未寫入) 子行程寫入頁 P 之後
父 ──┐ 父 ──▶ [頁 P 原本]
├──▶ [共享頁 P,唯讀]
子 ──┘ 子 ──▶ [頁 P 副本] ← 只複製這一頁
COW 讓 fork+exec 啟動新程式幾乎零複製成本,也讓 Redis 用 fork 做背景持久化(bgsave)時,子行程能拿到資料的「快照」而不阻塞主行程。
但 COW 有個著名陷阱:寫入會放大記憶體。如果 fork 後父行程持續修改大量頁,每次修改都複製一頁,原本「共享」的省記憶體效果會逐漸消失。更隱蔽的是——讀取也可能觸發複製:垃圾回收語言(如 Python 的引用計數、含標記的 GC)在「讀」物件時會更新物件標頭裡的計數或標記位元,這個寫入讓整頁被 COW 複製。這就是為什麼 fork 重的 Python/Ruby 服務的記憶體會莫名膨脹。
垃圾回收:自動記憶體管理的代價
C/C++ 要你手動 free;Java、Go、Python、JavaScript 則用垃圾回收器(GC)自動找出不再可達(unreachable)的物件並回收。這不是「免費」的——只是把成本從「程式設計師的腦力」轉移到「執行期的 CPU 與延遲」。
主流策略:
- 引用計數(reference counting):每物件記錄被引用次數,歸零即回收。優點是即時、可預測;缺點是無法回收循環引用(A 指 B、B 指 A 但外界都不可達),且每次賦值都要更新計數(多執行緒下還要原子操作)。CPython 用它為主,再加一個循環偵測器補洞。
- 追蹤式(tracing GC):從根集合(roots:堆疊、全域變數、暫存器)出發走訪所有可達物件,沒走到的就是垃圾。標記—清除(mark-sweep)是基礎;分代回收(generational GC)基於「多數物件早夭」的弱分代假說(weak generational hypothesis),把新生代(young gen)頻繁、快速地回收,老生代(old gen)少回收,大幅降低平均成本。
import gc, sys
a = []
b = []
a.append(b) # a -> b
b.append(a) # b -> a,形成循環引用
ref = sys.getrefcount(a)
del a, b # 外界不再引用,但循環讓引用計數不歸零
# 引用計數無法回收循環;要靠分代 GC 的循環偵測器
collected = gc.collect()
print(f"循環 GC 回收了 {collected} 個物件")
GC 的核心痛點是停頓(stop-the-world pause):傳統標記階段需要暫停所有應用執行緒以取得一致的物件圖。現代回收器(Go 的並行三色標記、Java 的 ZGC/Shenandoah)致力於把停頓壓到次毫秒級,代價是更複雜的讀/寫屏障(read/write barrier)與更高的吞吐量開銷。這又是一次「延遲 vs 吞吐量」的取捨。
重點回顧
- 單層分頁表會大到荒謬(48 位元位址下需 512 GB/行程);多級分頁表只為實際用到的子樹配置下層表,把開銷壓到 KB 級,代價是多次記憶體查找——由 TLB 吸收。
- TLB 是隱形瓶頸:覆蓋範圍僅數百 KB,存取模式分散時 TLB miss 主宰效能;大頁(huge page)可把單項覆蓋擴大 512 倍,但犧牲彈性與可 swap 性。
malloc不等於系統呼叫:使用者空間配置器向 OS 批發大塊、按 size class 零售小塊,因此會有內部碎片、free後常不還 OS、多執行緒有 arena。- 「用了多少記憶體」沒有單一答案:VSZ 含未碰過的保留區、RSS 高估共享、PSS 才公平分攤,而
Private_Dirty是最該優化的真實佔用。 - COW 與 GC 都是取捨:COW 讓 fork 近乎免費,但寫入(甚至引用計數的「讀取」)會放大記憶體;GC 省去手動管理,代價是執行期 CPU 與停頓延遲。
深入探討(研究所視角)
1. 分頁表走訪的硬體加速與安全副作用。 現代 CPU 在 MMU 內設有 page walk cache(如 Intel 的 Paging-Structure Caches),快取中間級的分頁表項以縮短 miss 後的走訪。但這條精密的轉換路徑也是 Meltdown/Spectre 一類微架構側通道(microarchitectural side channel)的攻擊面:推測執行(speculative execution)會在權限檢查完成前載入受保護頁,再透過 cache 時序洩漏內容。緩解手段 KPTI(Kernel Page Table Isolation)把核心與使用者分頁表分離,代價是每次系統呼叫都要切換 CR3 並沖刷 TLB,可量化地降低吞吐量——這是「安全 vs 效能」在記憶體管理層的直接體現。值得追的延伸:PCID(Process-Context Identifier)如何讓 TLB 不必全沖刷以減輕 KPTI 開銷。
2. 碎片化的理論界限。 使用者空間配置的外部碎片(external fragmentation)有可證明的下界。Robson(1971)證明:任何不可移動物件的配置器,在最壞情況下實際使用峰值為 $M$、最大區塊為 $n$ 時,可能需要 $\Theta(M \log n)$ 的記憶體。這意味著沒有任何 malloc 策略能在最壞情況下避免碎片——除非允許移動物件(compaction),而那正是追蹤式 GC(如複製式回收 copying collector)相對 malloc 的根本優勢:它能搬移存活物件、消除外部碎片,代價是更新所有指向被搬物件的指標(需要可被精確識別的指標,即 precise GC)。
3. 記憶體與並行的交會:RCU 與危險指標。 在無鎖(lock-free)資料結構中,「何時可以安全釋放一個已被移除但可能仍有讀者在存取的節點」是核心難題(the memory reclamation problem)。Linux 核心的 RCU(Read-Copy-Update)讓讀者零開銷地存取,寫者更新後延遲釋放舊版本,直到確認所有先前的讀者都已離開臨界區(grace period)。另一條路線是危險指標(hazard pointers,Michael 2004)。這把「記憶體何時可回收」從單行程問題提升為分散式同步問題,是作業系統、並行演算法與記憶體管理三者交會的前沿。
4. 延伸閱讀方向。 想深入的學生可循三條線:(a) 持久記憶體(persistent memory, NVM)如何打破「易失 RAM vs 非易失磁碟」的二分,逼迫重新設計配置器與故障一致性(failure atomicity);(b) 分代假說在不同工作負載下的失效情形,以及 region-based memory management(如 Rust 的所有權模型)如何在編譯期靜態保證安全而完全免去 GC;(c) 將 TLB、cache、NUMA 拓樸納入考量的 locality-aware allocator,這在多通道、多 socket 的伺服器上對效能有決定性影響。