
檔案系統:從 inode 到崩潰一致性
為什麼刪檔只在瞬間,硬碟卻能在斷電中保住你的資料
為什麼刪掉一個檔案,硬碟只「瞬間」就空出好幾 GB?
你或許注意過一件怪事:複製一部 4GB 的電影要等上好幾秒,但把它丟進資源回收筒再清空,幾乎是一瞬間的事。如果刪除真的要「把那 4GB 的內容抹掉」,理應跟複製一樣慢才對。
答案藏在作業系統管理儲存裝置的那一層軟體裡——檔案系統(file system)。刪除一個檔案時,系統多半不會去碰那 4GB 的資料本身,而只是改動了一小撮「描述這個檔案在哪裡」的記錄。理解這層「描述」與「資料本體」的分離,正是讀懂檔案系統的鑰匙。
檔案與目錄:把混亂的位元組變成可命名的抽象
硬碟、SSD 對作業系統來說,本質上是一個巨大的、按編號排列的儲存格陣列:第 0 號區塊、第 1 號區塊、第 2 號區塊……每個區塊(block)通常是 4KB。如果應用程式必須親自記住「我的論文存在第 81920 到第 81935 號區塊」,那將是一場災難。
檔案系統提供兩個核心抽象,把這片原始空間變得可用:
- 檔案(file):一段有名字的位元組序列。你不需要知道它實際落在哪些區塊,只要說「打開
thesis.docx」。 - 目錄(directory):一張「名字 → 檔案」的對照表,而且目錄本身也可以放進別的目錄,於是形成樹狀結構。
這個樹狀結構讓我們可以用路徑(path)來定位任何檔案。/home/alice/thesis.docx 從根目錄 / 出發,逐層往下走:先進 home,再進 alice,最後找到 thesis.docx。其中以 / 開頭的稱為絕對路徑(absolute path);相對於「目前所在目錄」描述的,例如 ../data/raw.csv,則是相對路徑(relative path),. 代表當前目錄,.. 代表上一層。
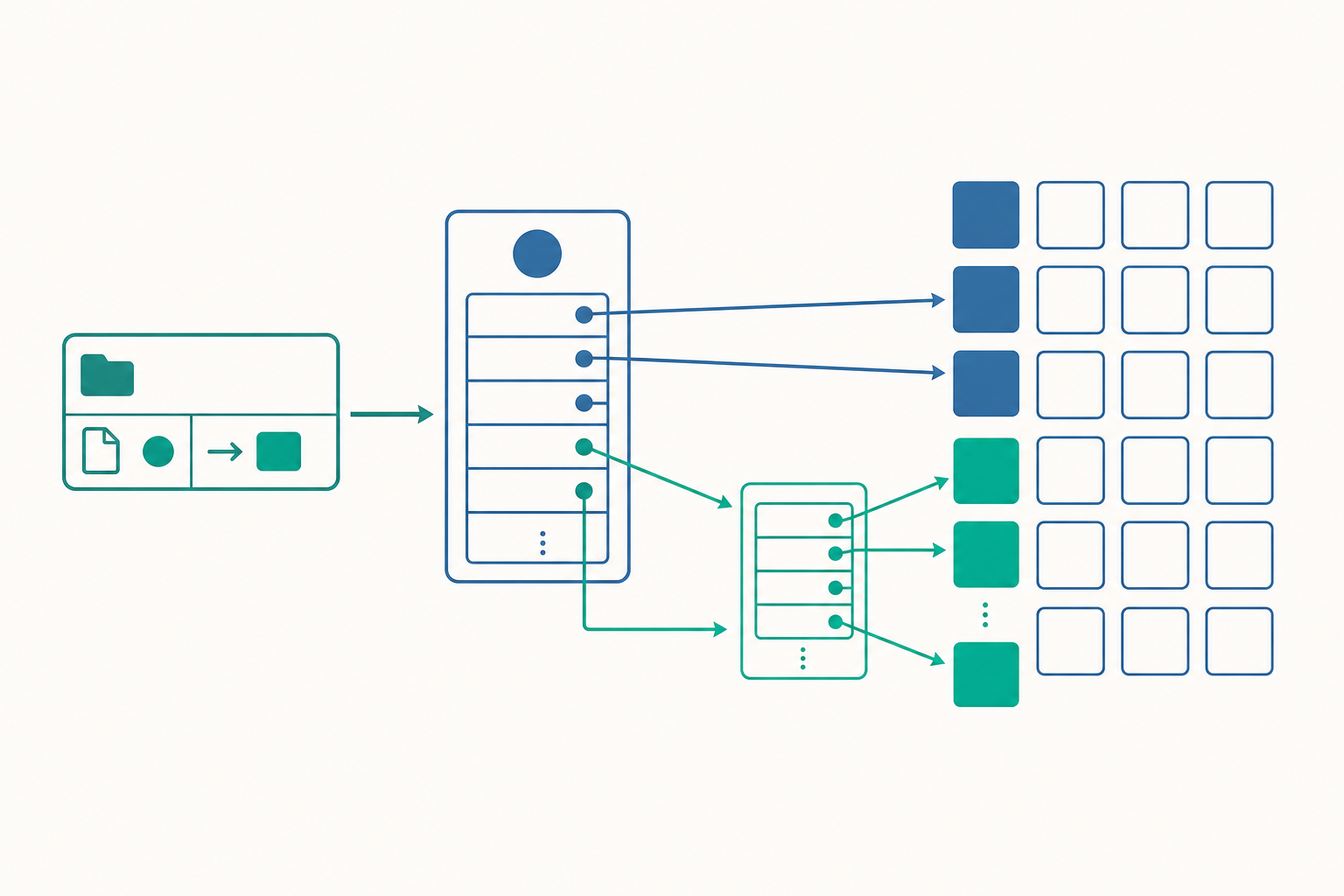
Metadata:檔案的「身分證」與資料本體分家
打開檔案總管,你看得到的不只是檔名,還有大小、修改時間、誰是擁有者。這些「關於檔案的資料」就是中繼資料(metadata),它和檔案的實際內容是分開儲存的。
在類 Unix 系統裡,每個檔案都對應一個 inode(index node 的縮寫),這是一個固定大小的結構,存放著除了「檔名」以外的幾乎所有 metadata:
| 欄位 | 內容 | 說明 |
|---|---|---|
| 檔案類型與權限 | mode |
是一般檔案、目錄還是連結,以及讀寫執行權限 |
| 擁有者 | uid / gid |
使用者與群組編號 |
| 大小 | size |
檔案有多少位元組 |
| 時間戳記 | atime / mtime / ctime |
最後存取、最後修改內容、最後修改 inode 的時間 |
| 連結數 | links_count |
有多少個檔名指向這個 inode |
| 資料指標 | block pointers |
真正的內容放在哪些區塊 |
值得注意的是:檔名並不在 inode 裡。檔名其實住在「目錄」這個特殊檔案中,目錄的內容就是一張張「檔名 → inode 編號」的對照。這個設計帶來一個漂亮的後果——同一個 inode 可以被多個檔名指向,這就是硬連結(hard link)。刪除檔案的真相也由此揭曉:所謂 rm,其實是把目錄裡那一筆對照刪掉,並讓 inode 的 links_count 減一;只有當連結數歸零、且沒有程式正開著它時,那些資料區塊才會被標記為可回收。回到開頭的疑問——刪除之所以快,是因為它動的只是這寥寥幾筆記錄,而非 4GB 的內容。
區塊配置:一個檔案的內容散在哪裡?
一個檔案往往佔用許多區塊,檔案系統必須記錄「這些區塊是哪些、順序如何」。歷史上有三種經典策略,理解它們的取捨,就理解了檔案系統設計的核心張力。
連續配置(contiguous allocation):把檔案放在一段相鄰的區塊,例如第 100 到 119 號。優點是讀取極快(磁頭不必跳來跳去),而且只要記住「起點 + 長度」兩個數字。缺點是會產生外部碎片(external fragmentation):刪刪增增之後,剩下一堆零散的小空洞,明明總空間夠卻塞不下一個大檔案。檔案要長大時也很尷尬,後面可能早被別人佔住了。
鏈結配置(linked allocation):每個區塊在自己內部留一個指標,指向檔案的下一個區塊,像一條鏈子。新增區塊很自由,沒有外部碎片問題。但代價是隨機存取極慢——想讀第 1000 個區塊,得從頭沿著鏈子走 1000 步;而且任何一個指標損壞,後面整串就斷了。
索引配置(indexed allocation):替每個檔案準備一個「索引區塊」,裡面按順序列出該檔案所有資料區塊的編號。想讀第 $k$ 個區塊?查索引表第 $k$ 項即可,隨機存取是 $O(1)$。Unix 的 inode 正是這個思路的精緻版本。
動手看一個例子
假設一個檔案佔用了 4 個資料區塊。三種策略各自如何記錄?
連續配置: start = 100, length = 4
→ 內容在 100, 101, 102, 103
鏈結配置: 目錄記住 head = 100
區塊100[資料|→201] 區塊201[資料|→088]
區塊088[資料|→305] 區塊305[資料|→ NULL]
索引配置: inode 的指標陣列 = [100, 201, 88, 305]
→ 第 k 個區塊 = 指標陣列[k],直接命中
要讀「第 3 個區塊」(索引從 0 算起,即區塊 305):
- 連續:直接算
100 + 3 = 103,但這裡剛好不適用,因為實際區塊是散開的——這正凸顯連續配置要求「不能散」。 - 鏈結:從 100 走到 201、走到 88、再走到 305,共 4 步。
- 索引:查
指標陣列[3] = 305,1 步到位。
權限:誰可以對這個檔案做什麼?
既然 inode 裡存著擁有者與權限位元,檔案系統就能擔任第一道存取控制的關卡。傳統 Unix 把使用者分成三類,每類各有讀(r)、寫(w)、執行(x)三種權限:
-rwxr-xr-- 1 alice staff 8192 thesis.sh
│└┬┘└┬┘└┬┘
│ │ │ └── others(其他人):r-- 只能讀
│ │ └───── group(同群組): r-x 可讀、可執行
│ └──────── owner(擁有者): rwx 可讀、可寫、可執行
└────────── 檔案類型:- 表一般檔案,d 表目錄
這九個位元常被寫成八進位的三位數:rwx = 111 = 7、r-x = 101 = 5、r-- = 100 = 4,所以上例就是 754。我們熟悉的 chmod 644 file 意思就是「擁有者可讀寫,群組與其他人只能讀」。
要特別釐清的是:對目錄而言,這三個位元的意義不同——讀(r)是「能列出目錄裡有哪些檔名」,寫(w)是「能在此目錄新增或刪除檔案」,執行(x)是「能穿越進入這個目錄」。這解釋了一個常見困惑:你可能對某個檔案沒有寫權限,卻仍能刪除它,因為刪除動作檢查的是「父目錄」的寫權限,而不是檔案本身的。權限機制的目的在於合法地保護資料與隔離使用者,使用時應遵循最小權限原則,只授予必要的存取能力。
重點回顧
- 檔案系統提供檔案與目錄兩個抽象,把原始區塊變成可命名、可用路徑定位的樹狀結構。
- metadata 與資料本體分離:類 Unix 系統用 inode 存放權限、大小、時間戳與資料區塊指標,而檔名住在目錄裡,因此一個 inode 可被多個檔名(硬連結)指向,刪除只是減少連結數。
- 區塊配置三策略各有取捨:連續讀取快但有外部碎片、鏈結有彈性但隨機存取慢、索引支援 $O(1)$ 隨機存取,是 inode 的設計基礎。
- Unix 權限以 owner / group / others 三類乘 r/w/x 三權限構成,目錄的 r/w/x 語意與檔案不同;刪檔檢查的是父目錄的寫權限。
- 權限與存取控制的目的是合法保護資料、隔離使用者,應遵循最小權限原則。
深入探討(研究所視角)
inode 的多層索引:用有限的指標定址巨大的檔案
inode 大小固定(常見為 256 位元組),卻必須能描述從幾 KB 到數 TB 的檔案,這看似矛盾。經典 ext 系列的解法是多層索引(multilevel index):inode 裡有 15 個區塊指標,其中前 12 個是直接指標(direct),各指向一個資料區塊;第 13 個是單層間接指標(single indirect),指向一個「裝滿資料區塊編號」的索引區塊;第 14、15 個則是雙層、三層間接指標。
這個設計的精妙在於它對檔案大小的非對稱友善:小檔案(12 個區塊以內,4KB 區塊下約 48KB)完全靠直接指標,零額外查表開銷——而絕大多數檔案都很小;大檔案才逐步動用間接層。若一個區塊能裝 $N$ 個指標(4KB 區塊、4 位元組指標時 $N=1024$),則可定址的最大區塊數約為:
$$12 + N + N^2 + N^3$$
存取一個區塊的成本因此與其所在「層級」相關,最壞情況為 $O(1)$ 常數次(最多三次間接讀取)。這種「常見情況快、極端情況仍可行」的設計哲學,在系統領域反覆出現。
崩潰一致性:日誌式檔案系統如何在斷電中存活
考慮一個看似簡單的動作——把一個資料區塊加進檔案。它其實要修改三處磁碟結構:(1) 在點陣圖(bitmap)標記該區塊已被佔用、(2) 更新 inode 的指標與大小、(3) 寫入資料區塊本身。問題來了:磁碟一次只能原子地寫一個區塊,若這三筆寫入進行到一半時突然斷電,檔案系統就會落入不一致狀態。
最危險的情境是:bitmap 說「這區塊已用」,但 inode 還沒指向它——這塊空間就此洩漏(leak),永遠拿不回來;更糟的是 inode 指向了某區塊,但 bitmap 仍標它「空閒」,日後它可能被配置給另一個檔案,造成兩個檔案共用同一區塊的災難性資料毀損。早年用 fsck 開機後全盤掃描修補,但 TB 級磁碟掃一次要數小時,顯然不可行。
日誌式檔案系統(journaling file system) 借用了資料庫的預寫式日誌(write-ahead logging, WAL) 思想:在真正改動最終位置之前,先把「我打算做哪些修改」成批寫到一塊專屬的日誌(journal)區。完整流程是:
- Journal write:把這次交易要改的 bitmap、inode、資料區塊內容寫進日誌。
- Journal commit:寫下一個 commit 標記,宣告「這筆交易已完整記錄」。這一步是原子的關鍵分界。
- Checkpoint:把日誌裡的內容實際寫回它們在磁碟上的最終位置。
崩潰可能發生在任何一步,但一致性恆能恢復:若斷電發生在 commit 標記寫成之前,重開機時這筆不完整交易直接被丟棄,當作沒發生;若 commit 已寫成,則重播(replay)日誌、把內容補寫到最終位置即可。無論如何,磁碟絕不會停在「改了一半」的中間態。開機復原只需掃描小小的日誌區(秒級),而非整顆磁碟。
這裡有一個關鍵的正確性要求:步驟 2 的 commit 標記,必須等步驟 1 的內容全部落盤後才能寫。否則磁碟控制器若為了效能而重排寫入順序,可能先寫好了 commit、交易內容卻還沒到位,replay 時就會把垃圾當成有效交易。檔案系統因此會在兩步之間插入寫入屏障(write barrier / flush),強制磁碟把快取清空。
實務上為了平衡效能與安全,日誌有不同模式。ext4 預設的 ordered 模式只把 metadata 寫進日誌,但保證資料區塊一定在 metadata commit 之前先寫到最終位置——這樣即使崩潰,也不會出現「inode 指向一塊裝著舊垃圾的區塊」的安全漏洞;代價是不保護資料本身的原子性。若要連資料一起進日誌(data journaling 模式),一致性最強,但每筆資料都寫兩次,吞吐量明顯下降。
與其他主題的連結
日誌式檔案系統的 WAL 與資料庫交易的 ACID、與分散式系統的兩階段提交(2PC)共享同一套「先記意圖、再執行、可重播」的思想脈絡。另一條演化路線是寫時複製(copy-on-write, CoW) 檔案系統,如 ZFS 與 Btrfs:它們從不就地覆寫,而是把修改寫到新區塊,最後再原子地切換根指標,天然規避了「改到一半」的問題,並能順帶支援快照(snapshot)。而在 SSD 普及後,由於快閃記憶體不能就地覆寫、且有抹寫次數壽命限制,日誌式與 log-structured 的設計理念(順序寫、集中回收)反而與底層硬體的特性高度契合,這也是當代儲存系統研究持續關注的方向。