
序向邏輯進階:時序、亞穩態與管線化
為什麼計數器會在某個頻率突然失靈?深入 setup/hold 不等式、metastability 與 pipelining 的物理極限
當「同步」變成一種奢侈:為什麼你的計數器會在某個時脈頻率突然失靈?
你已經在入門篇學會了正反器(flip-flop)如何記憶狀態、狀態圖(state diagram)如何描述一台有限狀態機(finite state machine, FSM)。那一切看起來都很乾淨:時脈邊緣一到,所有正反器整齊劃一地更新。
但真實的電路裡藏著一個殘酷的事實:正反器不是瞬間更新的,訊號在線路上傳播也需要時間。 當你把計數器的時脈頻率慢慢拉高,總有一刻,原本完美運作的電路會開始輸出垃圾——不是因為你的邏輯設計錯了,而是因為你撞上了時序(timing)的物理極限。
這一篇,我們不再談「正反器會記憶」這件入門事實,而是要深入:時序如何決定一個序向電路能跑多快、為什麼非同步輸入會讓系統「死」在一個曖昧的電壓上、以及工程師如何用 metastability 與 pipeline 的觀點重新理解序向邏輯。
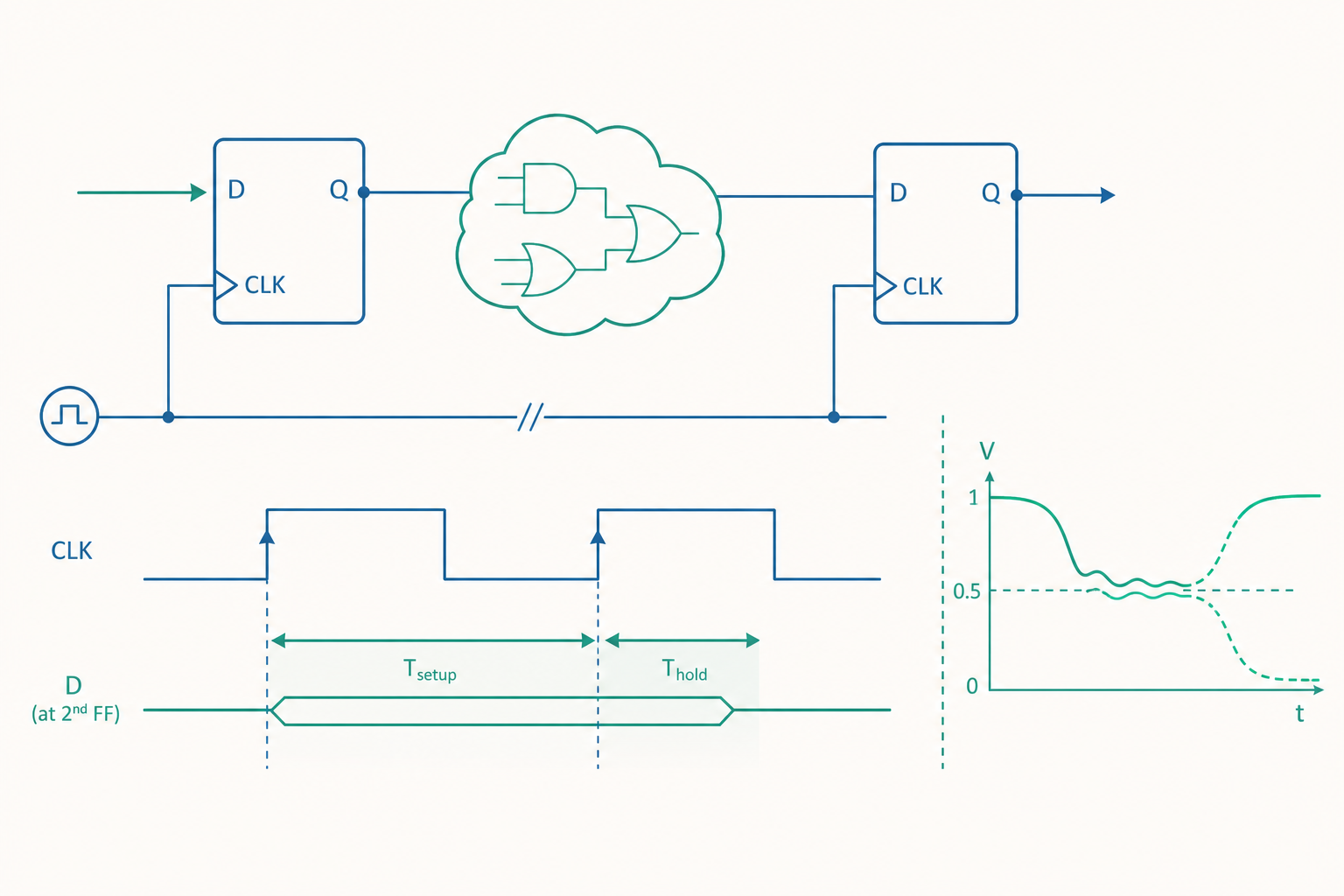
建立時間與保持時間:正反器的「不可打擾時段」
入門篇把 D 正反器當成一個理想元件:時脈上升緣一到,$Q$ 就等於那一刻的 $D$。進階的真相是,$D$ 必須在時脈邊緣前後一小段時間內保持穩定,正反器內部的鎖存才能可靠地捕捉到正確的值。
這兩段時間有名字:
- 建立時間(setup time, $t_{su}$):時脈邊緣到來之前,$D$ 必須已經穩定的最短時間。
- 保持時間(hold time, $t_{h}$):時脈邊緣到來之後,$D$ 必須繼續維持不變的最短時間。
如果 $D$ 在這個「不可打擾時段」內變動,正反器可能捕捉到一個介於 0 與 1 之間的中間值——這正是我們稍後要談的 metastability(亞穩態)。
還有第三個關鍵時間參數:
- 時脈到輸出延遲(clock-to-Q delay, $t_{cq}$):時脈邊緣之後,$Q$ 真正反映新值所需的時間。
這三個參數,決定了整個同步系統能跑多快。
推導最高時脈頻率:時序的核心不等式
考慮一條最常見的路徑:正反器 A 的輸出,經過一段組合邏輯(combinational logic),再餵進正反器 B 的 $D$ 輸入。兩個正反器吃同一個時脈。
在時脈的某個上升緣,A 更新輸出,這需要 $t_{cq}$;接著訊號穿越組合邏輯,花費傳播延遲 $t_{pd}$;訊號抵達 B 的 $D$ 輸入後,必須在下一個時脈上升緣之前 $t_{su}$ 就穩定下來。
設時脈週期為 $T_{clk}$,這條路徑要正確運作,必須滿足:
$$ t_{cq} + t_{pd} + t_{su} \le T_{clk} $$
換句話說,最高時脈頻率為:
$$ f_{max} = \frac{1}{T_{clk,\min}} = \frac{1}{t_{cq} + t_{pd,\max} + t_{su}} $$
注意這裡用的是組合邏輯的最長路徑延遲 $t_{pd,\max}$(稱為 critical path,關鍵路徑)。整個晶片跑多快,由最慢的那條路徑決定——這就是為什麼晶片設計者花大量心力去找並縮短關鍵路徑。
動手算一下:這顆計數器最快能跑多快?
假設你用的正反器規格為 $t_{cq} = 0.8\,\text{ns}$、$t_{su} = 0.5\,\text{ns}$、$t_{h} = 0.2\,\text{ns}$,而兩級正反器之間的組合邏輯(例如計數器的進位加法器)最長延遲 $t_{pd,\max} = 3.5\,\text{ns}$。
代入不等式:
$$ T_{clk,\min} = 0.8 + 3.5 + 0.5 = 4.8\,\text{ns} $$
$$ f_{max} = \frac{1}{4.8\,\text{ns}} \approx 208\,\text{MHz} $$
所以這顆計數器超過約 208 MHz 就會出現 setup violation(建立時間違規),輸出開始錯亂。這不是邏輯錯誤,而是物理極限。 想跑更快?只有兩條路:換更快的正反器(降低 $t_{cq}$、$t_{su}$),或把那條長的組合邏輯切短(pipelining,待會談)。
保持時間違規:一個無法靠「跑慢一點」解決的惡夢
setup violation 有個救贖:把時脈放慢就好。但 hold violation(保持時間違規)不會因為放慢時脈而消失——這是新手最容易踩的雷。
hold violation 發生在訊號跑得太快:A 更新後,新值太快穿過組合邏輯抵達 B,在 B 還沒可靠捕捉到「舊值」之前,就把 $D$ 改掉了。形式化的條件是,最短路徑必須夠長:
$$ t_{cq} + t_{pd,\min} \ge t_{h} $$
注意這裡完全沒有 $T_{clk}$!時脈週期再長都救不了——因為問題出在同一個時脈邊緣內部,不是兩個邊緣之間。
延續上面的數字,假設兩級之間有一條「直通」路徑(幾乎沒有組合邏輯),$t_{pd,\min} = 0.1\,\text{ns}$:
$$ t_{cq} + t_{pd,\min} = 0.8 + 0.1 = 0.9\,\text{ns} \ge t_{h} = 0.2\,\text{ns} \quad\checkmark $$
這條路徑安全。但若 $t_{cq}$ 很小(例如某些高速製程下 $t_{cq} = 0.1\,\text{ns}$)而 $t_h = 0.2\,\text{ns}$,就會違規。實務上修正方法是故意在短路徑插入緩衝器(buffer)或延遲元件,把 $t_{pd,\min}$ 墊高。聽起來很反直覺:我們竟然要「故意讓電路變慢」才能正確運作。
跨時脈域與亞穩態:當輸入不聽你的時脈指揮
到目前為止,我們假設所有訊號都被同一個時脈馴服。但真實系統裡,外界訊號(按鈕、另一個時脈域的資料、感測器中斷)是非同步(asynchronous)的——它們才不管你的時脈邊緣在哪裡。
當一個非同步訊號剛好在正反器的 setup/hold 窗口內變動,正反器可能進入 亞穩態(metastability):輸出 $Q$ 卡在 $V_{DD}/2$ 附近的某個既非 0 也非 1 的電壓,搖搖欲墜地停留一段不確定的時間,最後才隨機地落向 0 或 1。
亞穩態無法被完全消除——它是物理本質。但我們可以讓它「在你看到它之前就解決掉」的機率高到實務上可忽略。亞穩態解決的機率隨等待時間呈指數衰減,殘留失效率可用 mean time between failures(MTBF,平均故障間隔時間)量化:
$$ \text{MTBF} = \frac{e^{\,t_{r}/\tau}}{T_0 \cdot f_{clk} \cdot f_{data}} $$
其中 $t_r$ 是留給亞穩態解決的時間(通常是一個時脈週期),$\tau$ 與 $T_0$ 是正反器的物理常數,$f_{clk}$ 是取樣時脈頻率,$f_{data}$ 是非同步資料的變化頻率。
關鍵洞察是 $t_r$ 在指數的位置:多給一個時脈週期讓亞穩態消退,MTBF 就指數級暴增。 這正是「雙正反器同步器(two-flop synchronizer)」的原理——把非同步訊號連續通過兩級正反器,第一級可能進入亞穩態,但有一整個時脈週期讓它消退,第二級取樣到的幾乎一定是乾淨的 0 或 1。
看一個例子:同步器把 MTBF 從「幾秒」拉到「比宇宙年齡長」
假設某 FPGA 正反器 $\tau = 0.05\,\text{ns}$、$T_0 = 1\,\text{ns}$,系統 $f_{clk} = 100\,\text{MHz}$、非同步資料 $f_{data} = 1\,\text{MHz}$。
單級正反器,幾乎沒留解決時間($t_r \approx 0$):
$$ \text{MTBF} \approx \frac{e^{0}}{1\text{ns} \times 10^8 \times 10^6} = \frac{1}{10^{14}}\,\text{s} $$
這數字小於 1 秒,意思是每秒都在出事,完全不能用。
雙級同步器,給一整個時脈週期 $t_r = 10\,\text{ns}$ 解決:
$$ e^{\,t_r/\tau} = e^{\,10/0.05} = e^{200} $$
$e^{200} \approx 10^{86}$,於是:
$$ \text{MTBF} \approx \frac{10^{86}}{10^{14}}\,\text{s} = 10^{72}\,\text{s} $$
宇宙年齡約 $4.3 \times 10^{17}$ 秒。$10^{72}$ 秒遠遠超過——實務上等於「永遠不會因亞穩態出錯」。只多加一級正反器,failure rate 從不可接受變成天文數字級安全。這就是為什麼所有跨時脈域(clock domain crossing, CDC)的訊號都必須過同步器,這是數位設計的鐵律。
Pipelining:用「切碎關鍵路徑」換取更高吞吐量
回到 $f_{max}$ 那條不等式。如果你的關鍵路徑 $t_{pd,\max}$ 很長(例如一個 64 位元乘法器),$f_{max}$ 就被壓得很低。pipelining(管線化)的核心想法是:把長的組合邏輯切成數段,每段之間插入一排正反器(pipeline register)。
假設原本一條延遲 $12\,\text{ns}$ 的組合邏輯,切成 3 段各 $4\,\text{ns}$:
- 原本:$T_{clk} \ge 0.8 + 12 + 0.5 = 13.3\,\text{ns} \Rightarrow f_{max} \approx 75\,\text{MHz}$
- 管線化後:$T_{clk} \ge 0.8 + 4 + 0.5 = 5.3\,\text{ns} \Rightarrow f_{max} \approx 189\,\text{MHz}$
吞吐量(throughput)提升約 2.5 倍。代價是 latency(延遲):一筆資料現在要走 3 個時脈週期才能穿過整條管線,且多了 2 排正反器的面積與功耗。這是序向設計裡最經典的權衡:你不是在「讓電路變快」,而是在「用面積與 latency 換 throughput」。
現代 CPU 的深管線(十幾、二十級)正是這個思想的極致延伸,也帶來了分支預測錯誤要清空整條管線的代價——一切都源自這條樸素的時序不等式。
重點回顧
- 序向電路能跑多快,由 setup 不等式 $t_{cq} + t_{pd,\max} + t_{su} \le T_{clk}$ 決定,關鍵路徑(最慢路徑)說了算。
- setup violation 可以靠放慢時脈解決;hold violation 不行——它由 $t_{cq} + t_{pd,\min} \ge t_h$ 控制,與時脈週期無關,修法是替短路徑加緩衝器。
- 亞穩態(metastability) 是物理本質、無法消除,但解決機率隨等待時間指數衰減,MTBF 隨多給的時脈週期指數暴增。
- 雙正反器同步器 是處理跨時脈域非同步訊號的標準解法,只多一級就能把 MTBF 推到天文數字。
- pipelining 用插入暫存器切短關鍵路徑,以 latency 與面積換取更高 throughput——這是 throughput/latency 權衡的核心範式。
深入探討(研究所視角)
若你之後修數位 IC 設計、計算機結構或 VLSI,以下幾條延伸值得追下去。
1. 時脈偏斜(clock skew)與有用偏斜(useful skew)。 我們前面假設所有正反器同時收到時脈邊緣,但時脈樹(clock tree)的佈線使不同正反器的時脈到達時間有差 $\delta$。把 skew 納入後,setup 條件變為 $t_{cq} + t_{pd,\max} + t_{su} \le T_{clk} + \delta$,hold 條件變為 $t_{cq} + t_{pd,\min} \ge t_h + \delta$。有趣的是,刻意安排正向 skew 可以「借時間(time borrowing)」給關鍵路徑,這是 useful skew optimization 的基礎;但同一個 skew 會惡化 hold margin,兩者要一起求解。
2. 統計時序分析(statistical static timing analysis, SSTA)。 在先進製程(如 5nm、3nm)下,製程變異使 $t_{cq}$、$t_{pd}$ 不再是定值而是機率分布。傳統 corner-based STA 用最壞情況過度悲觀,SSTA 改以分布傳播,求整條路徑延遲的機率密度,讓設計者在 yield 與效能間做更精準的取捨。
3. 亞穩態的物理模型。 亞穩態本質是正反器的雙穩態系統被推到鞍點(saddle point / metastable equilibrium)。在相空間中,它對應一個不穩定平衡點,逃逸時間由系統小訊號時間常數 $\tau$(與電晶體跨導 $g_m$ 和節點電容 $C$ 相關,$\tau \approx C/g_m$)決定,逃逸過程是線性化後的指數發散——這正是 MTBF 公式中 $e^{t_r/\tau}$ 的來源。
4. 非同步電路(asynchronous / self-timed circuits)。 整篇我們都假設全域時脈。但存在另一套完全不用時脈的設計範式:用握手協定(handshake protocol,如 bundled-data 或 dual-rail 的請求/確認 req/ack)讓每個模組「做完才往下傳」。它免除了時脈樹的功耗與 skew 問題,且天然適應變異(跑多快取決於實際延遲而非最壞情況),代價是設計複雜、缺乏成熟 EDA 工具支援。Sutherland 的 micropipelines 與 NULL Convention Logic 是這個領域的經典起點。
5. 從時序到形式化驗證。 當 FSM 規模變大,手算時序與窮舉狀態都不可行。研究所層級會用 model checking(如時序邏輯 CTL/LTL)來證明「某個非法狀態永遠不會到達」「同步器後的訊號一定穩定」這類性質——把序向電路的正確性從「測試到沒出錯」提升為「數學上證明不會錯」。