
類比數位轉換進階:DNL、亞穩態與架構背後的真精度
為什麼規格書上的位元數常被吃掉?拆開 SAR 電荷重分配、流水線數位校正與 Σ-Δ 迴路,看清靜態與動態非理想如何決定一顆 ADC 真正能用到第幾位
為什麼規格書上的「12 位元」常常騙人
你買到一顆標稱 $12$ 位元的類比數位轉換器(ADC,Analog-to-Digital Converter),規格書斗大地寫著 $4096$ 階解析度。可是當你把它接到精密電橋、慢慢掃過整個輸入範圍,卻發現某幾個輸出碼從來不會出現——明明電壓平滑上升,數位碼卻從 $2047$ 直接跳到 $2049$,中間的 $2048$ 像被黑洞吞了。更糟的是,同一顆晶片在 $25\,^\circ\text{C}$ 量得好好的,搬到攝氏零下的戶外就開始偶發性地吐出完全錯誤的數字。
入門篇我們把 ADC 當成理想的「取樣+量化」兩步驟,量化誤差乾淨俐落地落在 $\pm\Delta/2$ 之內。但真實的轉換器是由電容、開關、比較器、運算放大器拼出來的類比電路,每個元件都會偏離理想。這一篇,我們要拆開這座橋的橋墩,看看 靜態非理想(static non-ideality)、動態誤差 與 架構層級的取捨 如何決定一顆 ADC 真正能用到第幾位。
靜態誤差:DNL、INL 與消失的碼
理想 ADC 的轉移函數是一道完美的階梯,每一階寬度都恰好是一個 LSB(最低有效位元,$\Delta = V_{\text{FS}}/2^N$)。真實的階梯卻寬窄不一,這就是微分非線性(DNL,Differential Non-Linearity)要刻畫的東西。對第 $k$ 個碼,定義
$$ \mathrm{DNL}[k] = \frac{W_k - \Delta}{\Delta} $$
其中 $W_k$ 是該碼實際對應的輸入電壓寬度。$\mathrm{DNL}=0$ 表示這一階完美;$\mathrm{DNL}=+0.5$ 表示這階比理想寬了半個 LSB。
關鍵的臨界值是 $\mathrm{DNL} = -1$:當某個碼的寬度被壓縮到零,意味著輸入電壓再怎麼掃,永遠不會落進這個碼——這就是「消失的碼」(missing code)的成因。一顆保證「無漏碼(no missing codes)」的 ADC,等於承諾所有 $\mathrm{DNL} > -1$。
把每一階的寬度誤差「累加」起來,得到的就是積分非線性(INL,Integral Non-Linearity),它衡量實際轉移曲線整體偏離理想直線多遠:
$$ \mathrm{INL}[k] = \sum_{i=1}^{k} \mathrm{DNL}[i] $$
INL 直接限制了 ADC 能達到的有效線性精度。一顆 $16$ 位元的 ADC,若 INL 高達 $\pm 4\ \text{LSB}$,那它在絕對精度上其實只值約 $14$ 位元——剩下的兩位被非線性吃掉了。靜態誤差還有兩位常客:偏移誤差(offset error)把整條曲線平移,增益誤差(gain error)讓曲線斜率偏離 $1$。這兩者可以靠校正(calibration)扣除,但 DNL/INL 這種逐碼的彎曲就難纏得多。
動手算一下:權重失配造成的 DNL 突波
逐次逼近型(SAR)ADC 的核心是一組二進位加權的電容陣列,理論權重應是 $\dots, 8C, 4C, 2C, C$。製程誤差讓最高位元那顆電容(MSB capacitor)不夠精準,假設一顆 $4$ 位元 SAR 的 MSB 電容實際權重不是理想的 $8\Delta$,而是 $7.4\Delta$(其餘位元正常)。當輸入電壓掃過碼 $0111 \to 1000$ 的交界,會發生什麼?
理想上,碼 $0111$ 對應 $7\Delta$,碼 $1000$ 對應 $8\Delta$,兩者相差一個乾淨的 LSB。但 MSB 一旦被打開,它只貢獻 $7.4\Delta$ 而非 $8\Delta$,於是碼 $1000$ 的起始電壓變成
$$ V_{1000} = 7.4\Delta $$
而前一個碼 $0111$(由 $4\Delta+2\Delta+\Delta$ 組成)的上界仍是 $7\Delta$。新碼的起點 $7.4\Delta$ 比舊碼終點 $7\Delta$ 高,中間 $7\Delta \to 7.4\Delta$ 這段 $0.4\Delta$ 寬的電壓區間沒有任何碼覆蓋——這是另一種病態,叫非單調(non-monotonic)或在更嚴重時造成漏碼。此處碼 $1000$ 的寬度也被擠壓:
$$ \mathrm{DNL}[1000] = \frac{W - \Delta}{\Delta} = \frac{0.6\Delta - \Delta}{\Delta} = -0.4 $$
這說明為什麼 SAR ADC 的精度幾乎完全押在「電容匹配(capacitor matching)」上。位元數越高、MSB 電容越大,要做到 $0.01\%$ 的匹配越困難,這也是為什麼高位元 SAR 普遍需要電容修整(trimming)或數位自我校正。
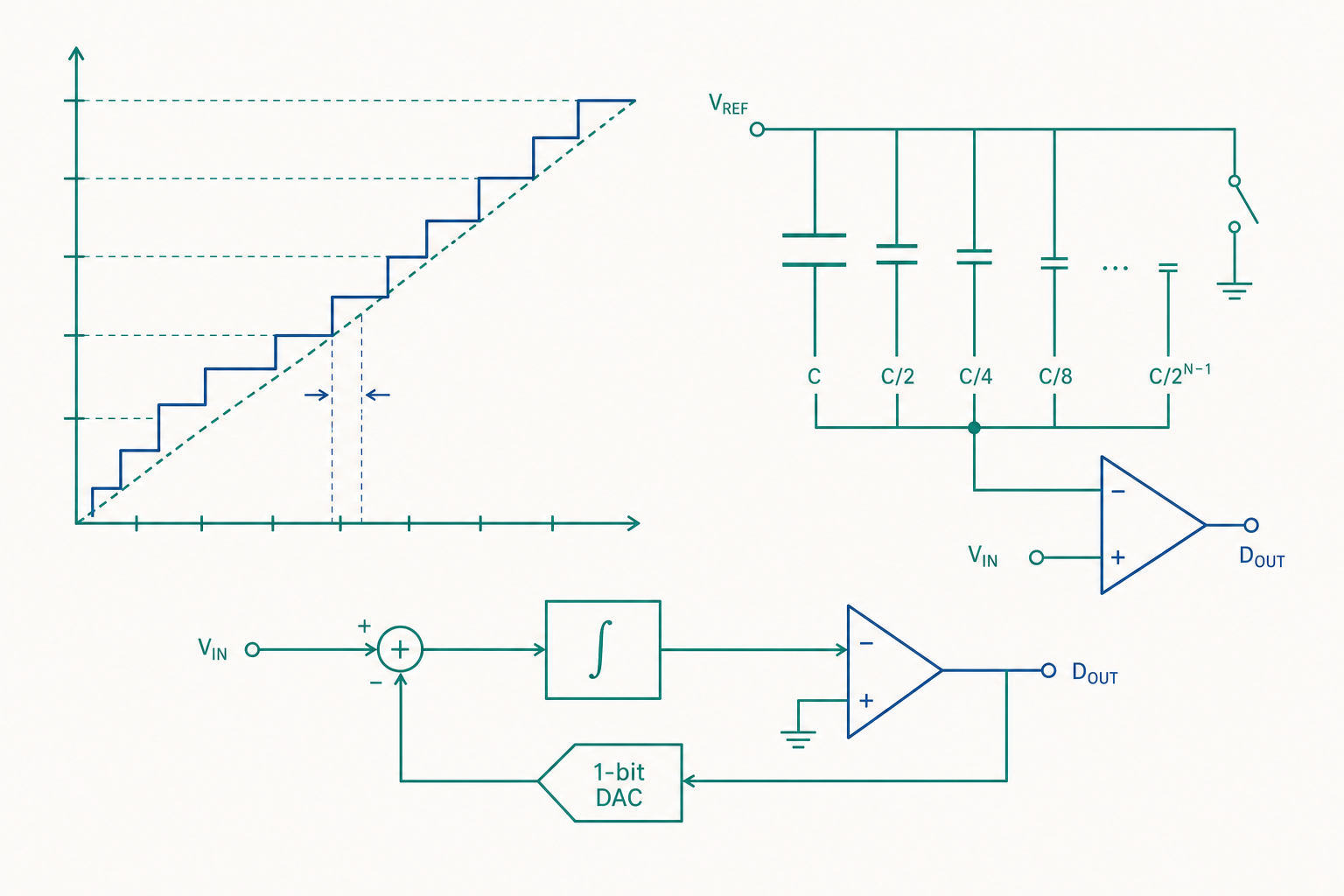
SAR 的真面目:電荷重分配
入門篇說 SAR「像猜數字遊戲」,但它究竟怎麼在電路上比較?答案是電荷重分配(charge redistribution)架構,它把取樣電容同時當成 DAC,極為精巧。
整個過程分三拍。取樣相(sample):所有電容的上極板接到比較器虛地,下極板接到輸入訊號 $V_{\text{in}}$,於是陣列總電荷被「凍結」成 $Q = -C_{\text{tot}} V_{\text{in}}$。保持相(hold):下極板切到地,由於電荷守恆,比較器輸入端電壓變成 $-V_{\text{in}}$。重分配相(redistribution):SAR 邏輯依序把每顆電容的下極板從地切到 $V_{\text{ref}}$,每切一次就相當於在比較器節點加上一個二進位加權的電壓增量。比較器判斷此刻電壓正負,決定該位元保留 $1$ 還是退回 $0$。
第 $k$ 步(測試第 $k$ 高位元)後,比較器看到的節點電壓可寫成
$$ V_x = -V_{\text{in}} + V_{\text{ref}} \sum_{i} \frac{b_i}{2^{i}} $$
逐位元逼近,直到節點電壓收斂到 $|V_x| < \Delta/2$。它的迷人之處在於:取樣、保持與 DAC 是同一組電容,省去獨立的取樣保持放大器,功耗極低,這正是 SAR 統治微控制器與物聯網感測前端的原因。代價是它必須 $N$ 個時鐘週期才出一個碼,每秒轉換次數受限。
看一個例子:比較器亞穩態與閃爍碼
SAR 每一步都靠比較器做一次二元判決。但比較器本質是一個高增益正回授的鎖存器(latch),當輸入差值極小——恰好落在判決門檻附近——它需要的「決斷時間」會發散。把比較器當成一階再生系統,輸出差電壓隨時間指數放大:
$$ \Delta V_{\text{out}}(t) = \Delta V_{\text{in}}\, e^{t/\tau} $$
其中 $\tau$ 是再生時間常數。要在分配給比較器的時間 $T_{\text{dec}}$ 內把一個微小的初始差 $\Delta V_{\text{in}}$ 放大到合法邏輯位準 $V_{\text{logic}}$,需要
$$ \Delta V_{\text{in}} > V_{\text{logic}}\, e^{-T_{\text{dec}}/\tau} $$
當輸入差小於這個值,比較器來不及做出明確判決,輸出停在中間的曖昧電壓——這就是亞穩態(metastability)。在高速 SAR 或 Flash ADC 中,亞穩態會以隨機的「閃爍碼(sparkle code)」或巨大誤碼出現,發生機率隨時鐘加快而上升。這就是為什麼前面提到「搬到低溫戶外就偶發吐錯數字」:溫度改變了元件偏壓與 $\tau$,把原本可接受的亞穩態機率推過了臨界。對策包括加長判決時間、加入冗餘位元做數位校正、或用格雷碼(Gray code)編碼讓單一誤判只造成 $1$ LSB 誤差。
流水線 ADC 與數位錯誤校正
當你需要 $14$ 位元、卻又要每秒上億次取樣(如 5G 基地台、醫學影像),SAR 太慢、Flash 太耗電,流水線(pipeline)ADC 是主流答案。它把一次高解析度轉換拆成數級(stage),每級只解析少數幾位元,再把「殘餘(residue)」放大後交給下一級——像工廠輸送帶,多個取樣同時在不同階段被處理。
每一級做三件事:用一個低解析度子 ADC 量出粗略碼 $D_i$、用子 DAC 還原這個碼、把輸入減去還原值得到殘餘、再乘上級增益 $G$。一個解析 $B$ 位元的標準級,殘餘函數為
$$ V_{\text{res}} = G\left( V_{\text{in}} - D_i \cdot \frac{V_{\text{FS}}}{2^{B}} \right), \quad G = 2^{B} $$
把殘餘放大 $2^B$ 倍,是為了讓它重新填滿下一級的滿刻度,使每一級都能用同樣的電路。問題來了:若某級的子 ADC 因為比較器偏移而判斷錯誤,這個錯誤會被後級放大、無法挽回嗎?
巧妙的解法是 1.5 位元/級的冗餘(redundancy) 與 數位錯誤校正(digital error correction)。每級故意多保留一點重疊範圍,讓殘餘永遠不會超出下一級的輸入量程;單級比較器即使有不小的偏移,只要不超過半級的容錯窗,最後在數位域把各級碼錯位相加就能自動修正。這個技巧讓流水線 ADC 可以容忍相當粗糙的內部比較器,把精度負擔轉移到後段數位邏輯——一個典型「用便宜的數位換昂貴的類比」的設計哲學。
動手算一下:兩級流水線的位元分配
設計一顆 $12$ 位元流水線 ADC,採兩級結構。若不考慮冗餘,理想上第一級解析 $6$ 位元、第二級解析 $6$ 位元。第一級的級增益應設為
$$ G_1 = 2^{6} = 64 $$
第一級量化後的殘餘最大值是 $\pm \Delta_1/2$($\Delta_1 = V_{\text{FS}}/2^{6}$),放大 $64$ 倍後恰好重新填滿 $\pm V_{\text{FS}}/2$,交給第二級再切 $6$ 位元。但實務上會改成「第一級 $6.5$ 位元、第二級 $6.5$ 位元、最後合併扣掉重疊的 $1$ 位元」,用那半位元的冗餘吸收第一級比較器偏移與級間增益誤差。這也解釋了為什麼流水線 ADC 規格書上各級位元加起來常常「多出來」——多的部分不是免費精度,而是拿去買容錯了。
Σ-Δ 的迴路:訊號與雜訊走不同的門
入門篇提到 Σ-Δ(Sigma-Delta)靠過取樣與雜訊塑形達到高解析度。這裡我們把它的迴路真正解出來,看清楚「為什麼訊號通過、雜訊被踢走」。
一階 Σ-Δ 調變器把量化器(常是 $1$ 位元比較器)放進一個含積分器的回授迴路。在 $z$ 域裡,把量化動作模型成「加入量化雜訊 $E(z)$」,可導出輸出
$$ Y(z) = \underbrace{z^{-1}}_{\text{STF}(z)} X(z) + \underbrace{(1 - z^{-1})}_{\text{NTF}(z)} E(z) $$
這條式子是整個 Σ-Δ 的靈魂。訊號轉移函數(STF) $z^{-1}$ 只是一個延遲,訊號原封不動通過;雜訊轉移函數(NTF) $(1-z^{-1})$ 卻是一個高通函數,在低頻($z \to 1$,即 $f \to 0$)時趨近於零。換句話說,量化雜訊在我們關心的低頻帶內被狠狠壓下去,被「塑形」推到高頻,再用數位低通濾波器一刀切掉。
把 $z = e^{j2\pi f/f_s}$ 代入 NTF,可得帶內雜訊的衰減形狀 $|1 - e^{-j\omega}| = 2\sin(\omega/2)$。對 $L$ 階調變器,NTF 變成 $(1-z^{-1})^L$,配合過取樣率 OSR,理論帶內 SNR 改善斜率達每倍頻 $(6L+3)\ \text{dB}$,遠勝單純過取樣的每倍頻 $3\ \text{dB}$。這就是為什麼一個 $1$ 位元的粗糙量化器,套上高階迴路與高 OSR,竟能在音訊帶內達到 $20$ 位元以上的等效精度。
代價是穩定性:高階迴路($L \ge 3$)的 NTF 增益太大會讓積分器飽和、迴路發散,因此實務上要把 NTF 的零點稍微挪離單位圓、限制其高頻增益(Lee 準則),用一點帶內雜訊換取穩定。此外,$1$ 位元 Σ-Δ 在直流或弱訊號輸入時,量化雜訊會退化成週期性的閒置音(idle tone),聽起來像背景哨音——這就引出下一個主題。
抖動:用雜訊治雜訊
量化是個強烈的非線性運算,當輸入訊號很小或很「規律」(如純直流、緩慢斜坡),量化誤差不再像入門篇假設的那樣是漂亮的白雜訊,而會與訊號強相關,產生諧波失真與閒置音。對策聽起來很反直覺:故意加入一點隨機雜訊,這叫抖動(dithering)。
在量化前注入一個振幅約 $1\ \text{LSB}$ 的隨機抖動訊號 $d$,可以打散量化誤差與輸入的相關性,把惱人的諧波「攤平」回近似白雜訊的背景。理論上,選用三角機率分布(TPDF)的抖動,能讓量化誤差的前兩階統計矩與輸入完全去相關——代價是底噪略微抬升約 $4.8\ \text{dB}$。聽覺與量測上,用平坦但稍高的底噪,換掉刺耳的離散假音,幾乎總是划算的交易。高階 Σ-Δ 與專業音訊 DAC 幾乎都內建抖動,這也是「加雜訊反而讓聲音更乾淨」的工程智慧。
重點回顧
- DNL/INL 才是真精度:標稱位元數只是上限。$\mathrm{DNL} \le -1$ 會造成漏碼,INL 直接決定絕對線性精度,常讓「$16$ 位元」實際只值 $13$、$14$ 位元。
- SAR 靠電荷重分配:取樣電容兼任 DAC,極省功耗;精度押在電容匹配上,MSB 電容失配會在碼中點製造 DNL 突波與非單調。
- 亞穩態是高速 ADC 的暗角:比較器再生時間有限,臨界輸入會卡在曖昧電壓,產生隨機閃爍碼;溫度與時鐘速率都會影響其機率。
- 流水線用數位救類比:冗餘位元 + 數位錯誤校正讓粗糙的內部比較器也能組出高速高解析 ADC,「多出來」的位元是買容錯。
- Σ-Δ 讓訊號與雜訊走不同門:STF 是延遲、NTF 是高通,把量化雜訊塑形推到高頻再濾掉;抖動則用一點隨機雜訊換掉刺耳的閒置音。
深入探討(研究所視角)
把這些非理想統合起來,研究所層級關心的是轉換器整體的頻譜純度與架構的資訊理論極限。
動態性能通常用一張 FFT 頻譜來定義:訊號雜訊與失真比(SINAD) 同時涵蓋雜訊與諧波,反推得有效位元數(ENOB) $= (\mathrm{SINAD}_{\text{dB}} - 1.76)/6.02$;而無雜散動態範圍(SFDR,Spurious-Free Dynamic Range) 則衡量訊號峰與最大雜散譜線之差,是通訊接收機最在意的指標,因為一根強烈的諧波雜散足以淹沒鄰近通道的弱訊號。INL 的「形狀」直接決定諧波分佈:弓形(bow-shaped)INL 主要生偶次諧波,S 形 INL 則生奇次諧波——靜態與動態誤差在頻域裡其實是同一件事的兩種投影。
高速 ADC 的另一個前沿是時間交錯(time-interleaved)架構:用 $M$ 顆較慢的子 ADC 輪流取樣,等效取樣率提升 $M$ 倍。但各通道之間的偏移失配、增益失配與時序偏斜(timing skew)會在頻譜上產生位於 $k\,f_s/M \pm f_{\text{in}}$ 的雜散音,限制 SFDR。校正這些失配是現代 GSps 級 ADC 的核心難題,常用背景式自適應演算法即時估測並補償。
理論的天花板由取樣抖動(aperture jitter)與熱雜訊共同設下。取樣時刻的隨機抖動 $\sigma_t$ 對一個頻率 $f_{\text{in}}$ 的輸入造成的 SNR 上限為
$$ \mathrm{SNR}_{\text{jitter}} = -20\log_{10}\!\left( 2\pi f_{\text{in}}\, \sigma_t \right) $$
注意它只與輸入頻率有關、與位元數無關——這意味著在高頻量測時,再多的位元也救不了一個時鐘抖動太大的系統。另一道牆是取樣電容的 $kT/C$ 熱雜訊:要把熱雜訊壓到 $N$ 位元量化雜訊以下,取樣電容必須夠大,而電容越大、驅動它的放大器就越耗電。於是「解析度、速度、功耗」構成一個無法同時最佳化的三角,業界以 Walden FoM $= P/(2^{\mathrm{ENOB}} \cdot f_s)$ 與 Schreier FoM 來量化這個取捨——每一代製程的進步,本質上都是在這個三角形裡多搶一點空間。最後,這些底層物理也呼應了入門篇提過的取樣定理:奈奎斯特保證的是「無混疊地保留資訊」,而 DNL/INL/抖動/熱雜訊決定的是「保留下來的資訊到底有多少位是可信的」——前者是充分條件,後者才是工程現實。