
組合邏輯進階:延遲、冒險與進位前瞻
當理想的布林模型遇上真實的傳播延遲,組合電路如何抖動、又如何加速
一個加法器到底「慢」在哪裡?
你已經知道組合邏輯(combinational logic)的輸出只看當下的輸入,沒有記憶。但這個乾淨的數學定義底下藏著一個工程界最頭痛的問題:真實的閘(gate)需要時間。 一個 4 位元漣波進位加法器(ripple-carry adder)在電路圖上看起來瞬間就算完了,可是當你把它做進晶片,最高位的進位訊號可能要等前面三級的進位一個接一個傳過來才會穩定。輸入一改變,輸出並不是立刻跳到正解,而是會先「抖」一陣子,跳過幾個錯誤的中間值,才安定下來。
入門篇告訴你組合邏輯「是什麼」;這一篇要談組合邏輯「實際上怎麼運作、為什麼會出錯、又怎麼設計得更快」。我們會碰到傳播延遲(propagation delay)、毛刺(glitch / hazard)、進位前瞻(carry lookahead),以及把多輸出函數一起化簡的系統方法。這些是把「邏輯正確」推進到「電路可用」的關鍵一哩路。
延遲:理想模型裂開的地方
在純布林代數的世界裡,$Y = A \cdot B$ 這個式子是瞬時成立的。但物理上,一個 AND 閘從輸入變動到輸出反映,需要一段傳播延遲 $t_{pd}$。這個延遲來自電晶體切換需要對寄生電容充放電,受製程、扇出(fan-out,一個輸出要驅動幾個下游輸入)、溫度與電壓影響。
我們通常分兩個方向描述延遲:
- $t_{pLH}$:輸出由低變高(Low to High)所需時間
- $t_{pHL}$:輸出由高變低(High to Low)所需時間
這兩者一般不相等,因為上拉(pull-up)和下拉(pull-down)路徑的電晶體強度不同。工程上常取兩者平均或最大值作為該閘的代表延遲。
當訊號要穿過多級閘,總延遲是關鍵路徑(critical path)——也就是從任一輸入到任一輸出之間,延遲最長的那條路徑——上各級延遲的總和:
$$ t_{pd,\text{total}} = \sum_{i \in \text{critical path}} t_{pd,i} $$
組合電路能跑多快,不是看平均路徑,而是看這條最慢的路徑。這也是為什麼數位設計裡「找出並縮短關鍵路徑」是一門核心功課。
動手算一下:漣波加法器的關鍵路徑
考慮一個 $n$ 位元漣波進位加法器。每一級全加器(full adder)的進位輸出 $C_{i+1}$ 必須等 $C_i$ 到位後才能算。設每級全加器從進位輸入到進位輸出的延遲為 $t_{c}$,從輸入到和(sum)輸出的延遲為 $t_{s}$。
最高位的和要正確,需要進位從第 0 級一路漣波到第 $n-1$ 級,再經過最後一級算出和:
$$ t_{pd} = (n-1)\,t_{c} + t_{s} $$
若 $t_c = 0.2\ \text{ns}$、$t_s = 0.3\ \text{ns}$,一個 32 位元加法器:
$$ t_{pd} = 31 \times 0.2 + 0.3 = 6.5\ \text{ns} $$
這代表此加法器最快只能跑約 $1/6.5\ \text{ns} \approx 154\ \text{MHz}$。延遲隨位元數線性成長——$O(n)$。對 64 位元處理器來說,這個線性關係是不能接受的。後面我們會看到進位前瞻如何把它壓到 $O(\log n)$。
毛刺與冒險:輸出為什麼會「抖」
延遲還帶來一個更隱蔽的問題:冒險(hazard)。即使布林邏輯告訴你某次輸入變動「輸出不應該改變」,實際電路卻可能短暫輸出一個錯誤值,這個短脈衝叫毛刺(glitch)。
冒險的根源是不等長路徑:同一個輸入訊號分岔成兩條路徑,一條經過反相器多繞一級,兩條到達同一個閘的時間不同,於是在切換的瞬間出現「兩條暫時不一致」的窗口。
看一個例子:靜態 1-冒險
考慮函數
$$ F = A \cdot \bar{C} + B \cdot C $$
固定 $A = 1$、$B = 1$,讓 $C$ 從 1 變成 0。代數上 $F$ 在兩種情況都是 1($C=1$ 時走 $B\cdot C$ 項,$C=0$ 時走 $A\cdot\bar C$ 項),照理應該穩定維持 1。
但實際上:當 $C$ 從 1 跌到 0,$B\cdot C$ 這一項立刻變 0;而 $A\cdot\bar C$ 這一項要等 $\bar C$($C$ 經過反相器)變成 1 才會升起。在這個反相器延遲的空窗裡,兩項都暫時是 0,輸出就掉出一個短暫的 0——這就是靜態 1-冒險(static-1 hazard):輸出本該維持 1 卻短暫掉到 0。
在卡諾圖(Karnaugh map)上,這對應到 $C=1$ 和 $C=0$ 兩個相鄰的 1-格分屬不同的乘積項(質含項,prime implicant),中間沒有一個共同的圈把它們蓋住。
消除方法:加冗餘項。 補上一個把這兩格一起圈住的共識項(consensus term):
$$ F = A \cdot \bar{C} + B \cdot C + A \cdot B $$
新增的 $A \cdot B$ 在邏輯上是多餘的(不改變真值表),但它在 $C$ 切換期間始終保持 1,像一座橋穩住輸出,把毛刺填平。共識項可由共識定理(consensus theorem)系統地找出:
$$ X \cdot Y + \bar{X} \cdot Z + Y \cdot Z = X \cdot Y + \bar{X} \cdot Z $$
等號右邊省略的 $Y \cdot Z$ 正是橋接 $X$ 與 $\bar X$ 兩項的共識項;做防冒險設計時,我們反過來把它加回去。
要注意的是:這招處理的是「單一輸入變動」造成的靜態冒險。當多個輸入同時改變時,可能出現動態冒險(dynamic hazard)——輸出在 0 與 1 之間連跳好幾次——那就無法只靠加冗餘項根除,通常要靠下游的時脈與正反器(flip-flop)在訊號穩定後才取樣來迴避。
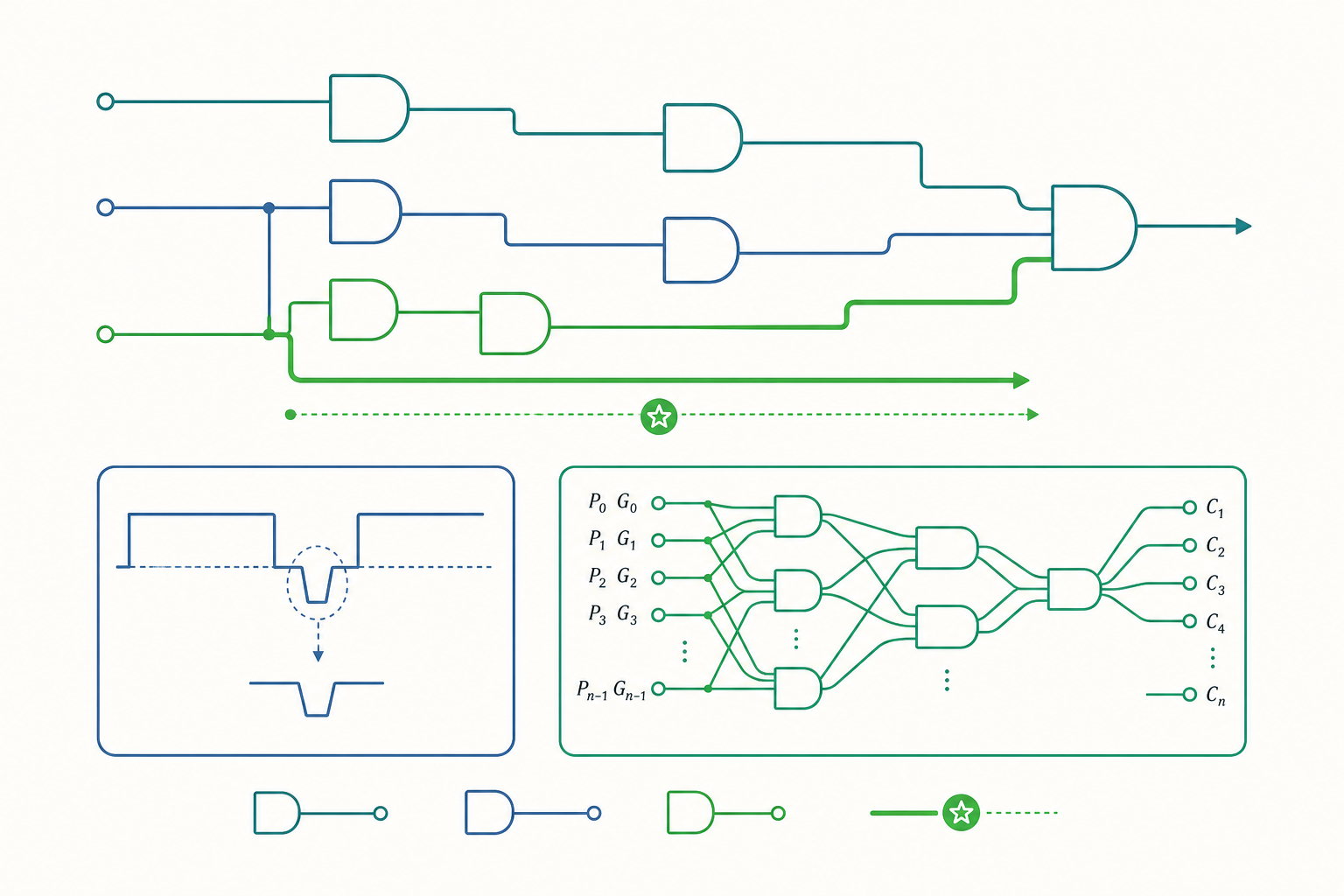
進位前瞻:把線性延遲壓成對數
回到加法器的速度問題。漣波加法器慢,是因為每一級都要等前一級的進位。進位前瞻加法器(carry-lookahead adder, CLA)的核心洞見是:進位其實可以從原始輸入直接平行算出,不必逐級等待。
對第 $i$ 位,定義兩個訊號:
- 產生(generate):$g_i = A_i \cdot B_i$ —— 不管進位進來與否,這一位自己就會產生進位
- 傳播(propagate):$p_i = A_i \oplus B_i$ —— 若有進位進來,這一位會把它傳遞出去
於是進位遞迴式可寫成:
$$ C_{i+1} = g_i + p_i \cdot C_i $$
把它展開,每一個進位都成為只依賴原始輸入與 $C_0$ 的兩級邏輯式:
$$ C_1 = g_0 + p_0 C_0 $$ $$ C_2 = g_1 + p_1 g_0 + p_1 p_0 C_0 $$ $$ C_3 = g_2 + p_2 g_1 + p_2 p_1 g_0 + p_2 p_1 p_0 C_0 $$
關鍵在於:所有 $g_i$、$p_i$ 可以在第一級同時算完,接著所有進位 $C_i$ 在第二級平行算出,不再一級等一級。理想化的 4 位元 CLA,進位延遲是固定的兩級閘延遲,與位元數無關。
當然,高位進位式的乘積項愈來愈長,扇入(fan-in)撐不住,實務上會把 CLA 切成 4 位元一組的區塊,再對區塊做第二層前瞻(block generate / block propagate),層層堆疊。這樣總延遲隨位元數呈 $O(\log n)$ 成長,而非漣波的 $O(n)$。這正是現代處理器算術單元(ALU)能在單一時脈週期完成 64 位元加法的基礎。
動手算一下:4 位元 CLA vs 漣波
沿用前面 $t_c = 0.2\ \text{ns}$、$t_s = 0.3\ \text{ns}$,並設 CLA 產生 $g/p$ 需 1 級延遲 $0.2\ \text{ns}$、平行算進位需 1 級 $0.2\ \text{ns}$、再算和需 $0.3\ \text{ns}$。
4 位元漣波:
$$ t_{pd} = 3 \times 0.2 + 0.3 = 0.9\ \text{ns} $$
4 位元 CLA:
$$ t_{pd} = 0.2_{(g,p)} + 0.2_{(\text{carry})} + 0.3_{(\text{sum})} = 0.7\ \text{ns} $$
4 位元時差距還小。但若是 16 位元:漣波 $= 15 \times 0.2 + 0.3 = 3.3\ \text{ns}$;而兩層區塊 CLA 約維持在 1 ns 出頭。位元數愈大,CLA 的對數優勢愈明顯——這就是用「面積與閘數」換「速度」的經典取捨。
多輸出最佳化:別把每個輸出單獨化簡
入門篇用卡諾圖化簡單一輸出函數。但真實電路(如加法器、編碼器、七段顯示解碼器)通常有多個輸出共用同一組輸入。如果你把每個輸出各自最簡化,往往會錯失一個更大的省法:讓多個輸出共享中間的乘積項。
考慮兩個輸出:
$$ F_1 = A B + A C, \qquad F_2 = A C + B C $$
各自最簡時,$F_1$ 用 $\{AB, AC\}$、$F_2$ 用 $\{AC, BC\}$,兩者都用到 $A C$。若把 $A C$ 這個閘做一次、兩邊共用,總閘數就比各做各的少。
這正是多輸出質含項(multiple-output prime implicant)的精神:化簡的目標不是「每個輸出最少項」,而是「整個電路總閘數最少」。系統化做法是把各輸出的最小項貼上「屬於哪個輸出」的標籤,找出可被多輸出共享的含項,再做覆蓋。當函數變多變大,這類問題交給邏輯合成工具(logic synthesis)以 Espresso 之類的啟發式演算法處理,但理解背後的「共享」直覺,能讓你讀懂合成報告、並在手算小電路時做出更聰明的設計。
重點回顧
- 延遲是組合邏輯的真實成本。 電路速度由關鍵路徑——延遲最長的輸入到輸出路徑——決定,而非平均路徑。
- 冒險源於不等長路徑。 單輸入變動可能造成靜態冒險;補上共識項這種冗餘邏輯可填平靜態毛刺,但動態冒險須靠後級正反器在訊號穩定後取樣迴避。
- 漣波加法器延遲是 $O(n)$。 進位逐級傳遞是瓶頸。
- 進位前瞻把進位寫成只依賴原始輸入的平行式,延遲降到 $O(\log n)$,代價是面積與扇入。 這是用閘數換速度。
- 多輸出函數要一起化簡。 目標是整體電路總閘數最少,透過共享乘積項,而非各輸出各自最簡。
深入探討(研究所視角)
往研究所層級走,組合邏輯的延遲分析會從「把每條路徑延遲加總」升級為靜態時序分析(static timing analysis, STA)。STA 不模擬任何輸入向量,而是用圖論方式在電路的有向無環圖上做最長路徑搜尋,計算每個節點的到達時間(arrival time)與所需時間(required time),兩者之差即時序裕度(slack)。slack 為負代表違反時序,這是現代 EDA 工具收斂時序的核心指標。STA 的價值在於它是窮舉式且不依賴測試向量的——它保證的是最壞情況路徑,而非某幾組輸入下的表現。
進位加法器的設計光譜也遠不止漣波與 CLA。前綴加法器(parallel-prefix adders)把進位計算看成一個結合性運算的前綴和(prefix-sum)問題,定義進位算子 $\circ$:
$$ (g, p) \circ (g', p') = (g + p \cdot g',\; p \cdot p') $$
由於此算子滿足結合律,可用平行前綴網路(如 Kogge-Stone、Brent-Kung、Sklansky)在 $O(\log n)$ 邏輯深度內算出所有進位。這些拓撲在「邏輯深度 vs 接線複雜度 vs 扇出」三者間各有取捨:Kogge-Stone 深度最淺但接線最密,Brent-Kung 接線稀疏但深度較深。處理器算術單元的設計,本質上就是在這個三維空間裡為特定製程選一個甜蜜點。
冒險問題在非同步電路(asynchronous circuits)中更是生死攸關。同步設計用時脈把毛刺「藏」在週期內、只在邊緣取樣穩定值,等於用時間冗餘換取對冒險的免疫。但非同步電路沒有全域時脈當保護傘,任何毛刺都可能被誤判為有效事件,因此必須採用無冒險邏輯或更嚴格的速度無關(speed-independent)/ 準延遲無關(quasi-delay-insensitive)設計範式,並引入完成偵測(completion detection)與雙軌編碼(dual-rail encoding)等機制。這也讓我們回頭看見組合邏輯的一個深層性質:它的「無記憶」是一種理想化抽象,而延遲恰恰是讓真實電路偷偷帶上「時間狀態」的縫隙——時序電路的種種挑戰,根源就埋在組合邏輯的這道縫隙裡。