
宇宙大尺度結構(進階):把星系地圖讀成精密宇宙學
從兩點相關函數、功率譜到紅移空間扭曲——一張看似凌亂的星系分佈,如何成為量測暗能量與檢驗重力的鋒利探針
為什麼一張「亂糟糟」的星系地圖,能精準回答暗能量的問題?
入門篇帶你走過了宇宙網(cosmic web)的長相:纖維、節點、空洞,以及它如何從十萬分之一的密度漣漪長成。但若你把一張真正的史隆數位巡天(SDSS)星系地圖攤開來看,第一印象其實是「凌亂」——幾億個亮點散落各處,纖維時隱時現,沒有兩條一模一樣。問題來了:宇宙學家如何從這片看似主觀的圖案中,擠出像哈伯常數、暗能量狀態方程那樣精確到百分之幾的數字?
答案是:我們從來不直接「看圖說故事」。大尺度結構真正的語言是統計。任何一張星系分佈,都被視為某個底層機率場的一次隨機抽樣;我們關心的不是哪個星系在哪裡,而是這個場的統計性質——它有多「成團」、在哪個尺度上振盪、隨時間長多快。本篇要談的,正是這套把「亂糟糟」轉譯成可檢驗物理的工具,以及它為何能成為當代精密宇宙學最鋒利的刀。
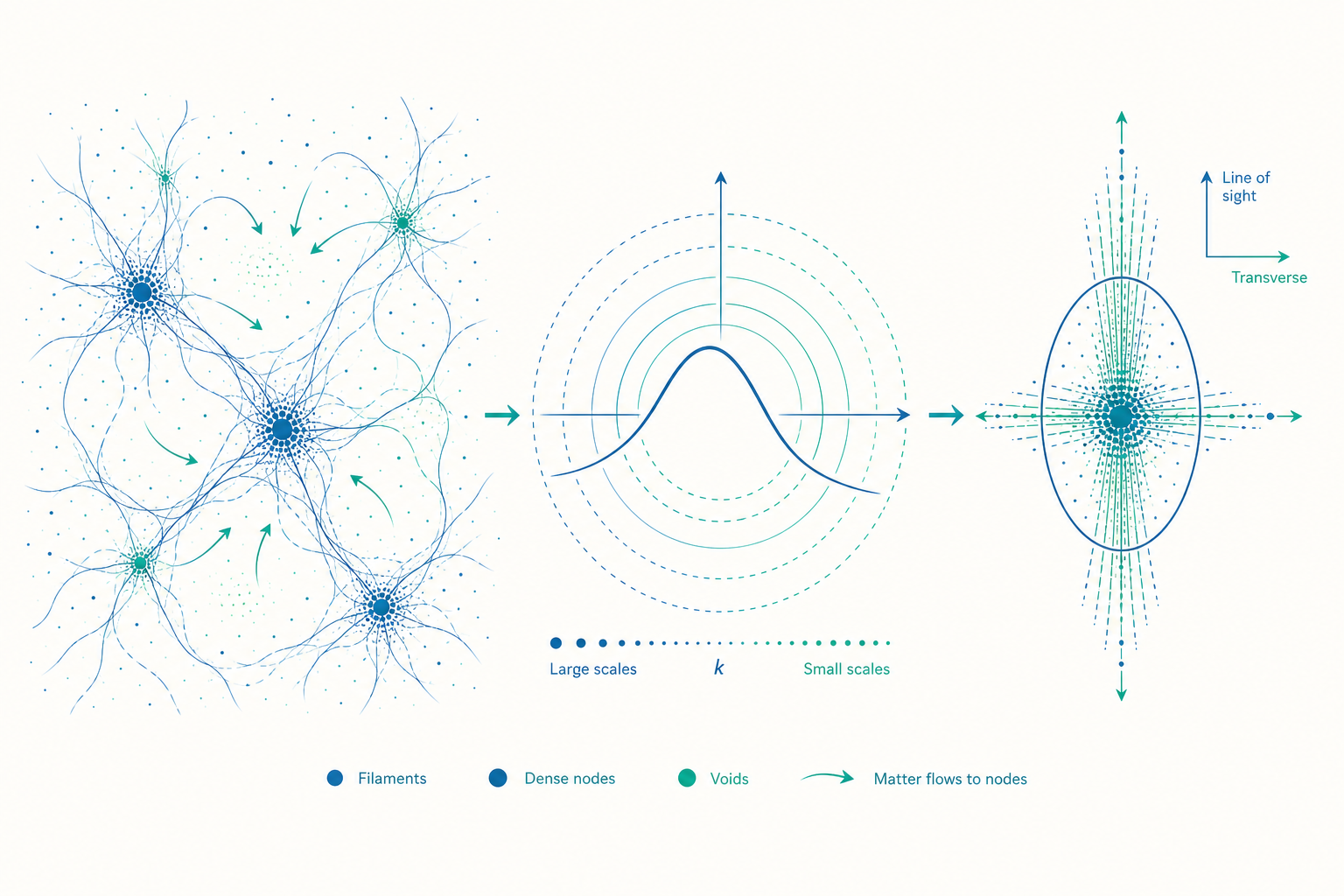
兩點相關函數:成團程度的數學定義
要量化「星系有多愛聚在一起」,最基本的工具是兩點相關函數(two-point correlation function) $\xi(r)$。它的定義很直觀:相對於完全隨機(泊松)分佈,在距離某星系 $r$ 處、體積 $\mathrm{d}V$ 內找到另一個星系的「超額機率」。
$$\mathrm{d}P = \bar{n}\,[1 + \xi(r)]\,\mathrm{d}V$$
其中 $\bar{n}$ 是星系的平均數密度。若 $\xi(r) = 0$,代表該尺度上星系彼此獨立、純隨機;$\xi(r) > 0$ 代表比隨機更密集(成團);$\xi(r) < 0$ 代表比隨機更稀疏(反聚集,正是空洞的特徵)。
觀測上,星系的 $\xi(r)$ 在小尺度($r \lesssim 10 \ \text{Mpc}/h$)可以漂亮地用冪律描述:
$$\xi(r) \approx \left(\frac{r}{r_0}\right)^{-\gamma}, \qquad \gamma \approx 1.8, \quad r_0 \approx 5 \ \text{Mpc}/h$$
這裡 $r_0$ 稱為「相關長度(correlation length)」,是 $\xi=1$ 的尺度,約 $5$ 百萬秒差距(以 $h = H_0/100$ 表示,免去哈伯常數不確定性的標準寫法)。$\gamma \approx 1.8$ 這個冪次幾十年來在各代巡天中驚人地穩定,本身就是重力塑造結構的指紋。
實務上怎麼算 $\xi(r)$?最常用的是 Landy–Szalay 估計量,它比較「真實星系兩兩配對數(DD)」、「隨機點兩兩配對數(RR)」與「真實—隨機交叉配對數(DR)」:
$$\hat{\xi}(r) = \frac{DD - 2\,DR + RR}{RR}$$
之所以要造一群「隨機點」陪襯,是因為巡天有複雜的邊界、天區遮罩與選擇效應;用同樣幾何的隨機目錄當分母,這些系統效應大致會被約掉。這是一個關鍵心法:大尺度結構分析的精度,常常不取決於你的星系,而取決於你多懂自己的隨機目錄。
功率譜:把宇宙網拆成不同尺度的波
$\xi(r)$ 活在「位置空間」,但結構成長的物理在「波數空間」更乾淨。對密度對比場 $\delta(\mathbf{x})$ 做傅立葉轉換,得到各個波模 $\delta(\mathbf{k})$,其變異數就是功率譜(power spectrum) $P(k)$:
$$\langle \delta(\mathbf{k})\,\delta^*(\mathbf{k}') \rangle = (2\pi)^3 \, P(k)\,\delta_D^3(\mathbf{k} - \mathbf{k}')$$
直覺上,$P(k)$ 告訴你「尺度 $\lambda \sim 2\pi/k$ 的起伏有多強」。大 $k$(小尺度)、小 $k$(大尺度)。功率譜與相關函數其實是同一資訊的兩種表達——它們互為傅立葉變換對:
$$\xi(r) = \int \frac{\mathrm{d}^3 k}{(2\pi)^3}\, P(k)\, e^{i\mathbf{k}\cdot\mathbf{r}}$$
為什麼宇宙學家偏愛 $P(k)$?因為在線性區(大尺度、$\delta \ll 1$),不同波模彼此獨立演化、互不耦合。每個 $\delta(\mathbf{k})$ 都按入門篇提過的線性成長因子 $D(a)$ 同步放大,於是整個功率譜的形狀被凍結、只有振幅隨時間長:
$$P(k, a) = D^2(a)\, P_{\text{lin}}(k)$$
這種「各尺度獨立、整體等比例長大」的乾淨行為,讓 $P(k)$ 成為連接早期宇宙(原初功率譜)與晚期觀測(星系分佈)的理想橋樑。
功率譜有個標誌性形狀:在某個特徵波數 $k_{\text{eq}}$ 處出現轉折(turnover)。比 $k_{\text{eq}}$ 大的尺度,$P(k) \propto k^{n_s}$,其中 $n_s \approx 0.965$ 是原初譜指數(接近但略小於 1,這個微小偏離是暴脹理論的關鍵預測之一);比 $k_{\text{eq}}$ 小的尺度則被壓抑。轉折發生的位置對應「物質—輻射相等時期(matter-radiation equality)」進入視界的尺度——在輻射主導期,過快的膨脹壓制了結構成長(這稱為 Mészáros 效應),於是小尺度功率被相對削弱。換句話說,$P(k)$ 的轉折,是宇宙能量組成在結構上刻下的烙印。
動手算一下:星系數量、體積與「為什麼大尺度這麼難測」
宇宙學測量大尺度功率譜時,最大的敵人之一是樣本變異(cosmic variance):在最大的尺度上,可觀測宇宙裡能放進去的獨立波模很少,統計起來天生不準。我們來估個量級。
假設一個巡天涵蓋共動體積 $V = 1 \ (\text{Gpc}/h)^3$,想測波長 $\lambda = 150 \ \text{Mpc}/h$ 附近的模(正好是 BAO 尺度)。對應波數 $k \approx 2\pi/\lambda$。在波數空間,一個球殼 $k$ 到 $k+\Delta k$ 內的獨立模數約為:
$$N_{\text{modes}} \approx \frac{4\pi k^2\,\Delta k}{(2\pi)^3 / V} = \frac{V\,k^2\,\Delta k}{2\pi^2}$$
取 $k \approx 0.042 \ h/\text{Mpc}$、$\Delta k \approx 0.01 \ h/\text{Mpc}$、$V = 10^9 \ (\text{Mpc}/h)^3$:
$$N_{\text{modes}} \approx \frac{10^9 \times (0.042)^2 \times 0.01}{2\pi^2} \approx \frac{10^9 \times 1.76\times10^{-5}}{19.7} \approx 8.9 \times 10^{2}$$
也就是大約 $900$ 個獨立模。功率譜測量的相對誤差約為 $1/\sqrt{N_{\text{modes}}} \approx 1/\sqrt{900} \approx 3.3\%$。
這個簡單估算揭露了一件深刻的事:要把大尺度誤差壓到 $1\%$,模數得增加約 10 倍,巡天體積也得跟著放大約 10 倍。 這正是為什麼 DESI、Euclid 這類新一代計畫要拼命擴大巡天天區與紅移深度——不是貪多,而是被宇宙的統計極限逼著走。可觀測宇宙只有一個,最大尺度上能抽的「樣本」就那麼多,這是物理硬限制,再厲害的望遠鏡也無法繞過。
紅移空間扭曲:缺陷如何變成寶藏
入門篇用哈伯—勒梅特定律把紅移換成距離。但這裡藏著一個微妙的問題:星系除了隨宇宙膨脹退行,還有自己的本動速度(peculiar velocity)——也就是被周圍重力拉扯產生、疊加在哈伯流之上的額外運動。我們測到的紅移其實是兩者之和:
$$cz_{\text{obs}} = cz_{\text{cosmo}} + v_{\text{pec},\parallel}$$
本動速度沿視線方向的分量會「污染」距離推算,使我們畫出的三維地圖在視線方向被扭曲——這稱為紅移空間扭曲(redshift-space distortions,RSD)。它有兩種截然不同的面貌:
Fingers of God(上帝之指):在已塌縮的星系團內部,星系繞質心高速亂飛(每秒上千公里)。這些隨機本動速度讓同一團星系在紅移空間被「拉長」成沿視線方向的細條,看起來像一根根指向觀測者的手指。這是小尺度、非線性的效應。
Kaiser 效應(大尺度壓扁):在尚未塌縮的大尺度上,物質正整體地朝高密度區流入。流入的一側星系本動速度朝我們、另一側遠離我們,淨效果是讓結構在紅移空間沿視線方向被「壓扁」,使密度等高線變得比真實更扁平。
乍看之下,RSD 是把好好的地圖搞亂的「缺陷」。但宇宙學家的精彩反轉在於:這個扭曲量本身正比於物質流動的速度,而流速正是結構成長速率的直接反映。 Kaiser 在線性區給出,紅移空間功率譜相對真實空間多了一個與視線夾角 $\mu = \cos\theta$ 有關的因子:
$$P_s(k, \mu) = \left(1 + \beta\,\mu^2\right)^2 P_r(k), \qquad \beta = \frac{f}{b}$$
這裡 $b$ 是星系偏置(galaxy bias,星系比暗物質更成團的倍率),而 $f$ 是我們真正想要的寶物——結構成長率(growth rate):
$$f \equiv \frac{\mathrm{d}\ln D}{\mathrm{d}\ln a} \approx \Omega_m(a)^{\gamma}, \qquad \gamma \approx 0.55$$
$f$ 衡量「結構成長有多快」,而它對重力理論極度敏感。廣義相對論預測 $\gamma \approx 0.55$;許多修改重力(modified gravity)理論則給出不同的 $\gamma$。於是,原本擾人的紅移扭曲,搖身一變成了檢驗愛因斯坦重力在宇宙尺度是否仍成立的探針。實務上量到的是組合量 $f\sigma_8$($\sigma_8$ 是 $8 \ \text{Mpc}/h$ 球內密度起伏的均方根,後面會談),因為它不依賴難以獨立測定的偏置 $b$。一個原本的「測量缺陷」,最終成了宇宙學最重要的成長率觀測量之一——這是大尺度結構研究裡反覆出現的美學。
從線性到非線性:宇宙網是怎麼「織」出來的
入門篇說過,當 $\delta$ 接近 $1$,線性理論失效。那纖維與空洞這種高度非線性、又帶方向性的圖案,究竟從何而來?關鍵洞見來自 澤爾多維奇近似(Zel'dovich approximation)。
澤爾多維奇的想法極其優雅:與其追蹤密度怎麼長,不如追蹤物質粒子怎麼移動。每個粒子從初始(拉格朗日)位置 $\mathbf{q}$ 出發,位移正比於初始重力場:
$$\mathbf{x}(\mathbf{q}, t) = \mathbf{q} + D(t)\,\boldsymbol{\psi}(\mathbf{q})$$
其中 $D(t)$ 是線性成長因子、$\boldsymbol{\psi}$ 是由初始位能決定的位移場。神奇之處在於:結構塌縮的形態,取決於位移場梯度張量(可視為初始潮汐場)的三個本徵值 $\lambda_1 \ge \lambda_2 \ge \lambda_3$。物質總是沿最大壓縮方向(最大本徵值)先塌縮,於是:
- 三個方向都不太壓縮 → 仍是低密度的空洞;
- 沿一個方向先塌縮 → 物質擠成一片牆(pancake / sheet);
- 再沿第二個方向塌縮 → 收成一條纖維(filament);
- 三個方向都塌縮 → 聚成一個節點(node),也就是星系團。
這就是宇宙網幾何的物理起源:不是巧合,而是初始潮汐場本徵結構在重力下展開的必然層級。現代的「宇宙網分類器」(如 T-web、Hessian 方法)正是計算每一點密度場或潮汐場的本徵值,依其正負個數把空間自動標記為空洞/牆/纖維/節點。澤爾多維奇近似在 $\delta \sim 1$ 前都驚人地準確,之後則需 N 體數值模擬(N-body simulation) 接手——把數十億顆粒子放進虛擬宇宙,逐步積分牛頓重力,讓宇宙網在電腦裡自己長出來。
看一個例子:σ8 與「結構成熟度」
我們常用一個單一數字概括「今日宇宙有多成團」:$\sigma_8$。它定義為半徑 $8 \ \text{Mpc}/h$ 的球內,密度對比 $\delta$ 的均方根:
$$\sigma_8^2 = \langle \delta_R^2 \rangle \Big|_{R = 8\,\text{Mpc}/h} = \int \frac{\mathrm{d}^3k}{(2\pi)^3}\, P(k)\, |W(kR)|^2$$
其中 $W(kR)$ 是半徑 $R$ 的球形窗函數。為什麼挑 $8 \ \text{Mpc}/h$?歷史上這是個經驗選擇——在這個尺度上,亮星系的 $\delta$ 起伏恰好約為 $1$(也就是 $\sigma_8 \approx 1$ 量級),正好坐在線性與非線性的交界,量起來既穩定又敏感。
當代觀測給出 $\sigma_8 \approx 0.81$。我們可以反推:在 $8 \ \text{Mpc}/h$ 球內,密度起伏的典型振幅約 $81\%$,已經是「接近 1」的非線性門檻——這定量地說明,今日宇宙在十百萬秒差距尺度上「剛好」成熟到開始塌縮成結構。
更有意思的是把它接回成長率。$\sigma_8$ 隨時間正比於成長因子 $D(a)$:$\sigma_8(a) = D(a)\,\sigma_8(0)/D(0)$。於是 RSD 測到的 $f\sigma_8$ 同時鎖住了「結構有多成熟($\sigma_8$)」與「結構長多快($f$)」。把不同紅移的 $f\sigma_8(z)$ 串成一條曲線,就能檢驗它是否符合廣義相對論在 $\Lambda$CDM 下的預測——目前數據與標準模型大致相符,但低紅移端是否有輕微偏低(即所謂 $S_8$ 張力),仍是當前研究的熱點。
重點回顧
- 大尺度結構的真正語言是統計:我們不研究單一星系,而是把分佈視為機率場的抽樣,用兩點相關函數 $\xi(r)$ 與功率譜 $P(k)$(兩者互為傅立葉對)量化成團程度。
- $P(k)$ 在線性區各波模獨立、整體按 $D^2(a)$ 等比成長,並在 $k_{\text{eq}}$ 處出現轉折,烙印著物質—輻射相等時期與宇宙能量組成。
- 紅移空間扭曲(RSD) 表面上是本動速度造成的地圖缺陷(Fingers of God 與 Kaiser 效應),實則是測量結構成長率 $f \approx \Omega_m^{0.55}$ 的探針,可用來檢驗重力理論。
- 澤爾多維奇近似用初始潮汐場的本徵值解釋宇宙網幾何:依塌縮方向數,自然產生空洞→牆→纖維→節點的層級。
- $\sigma_8 \approx 0.81$ 概括今日結構成熟度,與 $f$ 組成的 $f\sigma_8$ 是當代精密宇宙學最關鍵的成長率觀測量之一。
深入探討(研究所視角)
暈質量函數與偏置:把暗物質暈接到可見星系
統計工具描述的是底層(主要是暗物質)密度場,但我們觀測到的是星系——兩者之間隔著暗物質暈(dark matter halo) 與偏置(bias) 的橋樑。Press–Schechter 理論及其延伸(excursion set / Sheth–Tormen)給出暈質量函數(halo mass function):單位體積、單位質量區間內、質量為 $M$ 的暈的數密度
$$\frac{\mathrm{d}n}{\mathrm{d}M} = \frac{\bar{\rho}_m}{M}\, f(\nu)\, \frac{\mathrm{d}\ln\nu}{\mathrm{d}M}, \qquad \nu = \frac{\delta_c}{\sigma(M)}$$
其中 $\delta_c \approx 1.686$ 是球塌縮模型給出的「臨界線性密度對比」(線性外推下,密度起伏超過此值即視為已塌縮),$\sigma(M)$ 是質量尺度 $M$ 對應的密度起伏均方根。$\nu$ 是「峰高」——越高代表越稀有、越大的暈。這個架構解釋了為何巨大星系團如此稀少(高 $\nu$ 指數壓抑),以及暈數目對 $\sigma_8$ 與 $\Omega_m$ 的指數級敏感性,使星系團計數(cluster counts) 成為另一條獨立的宇宙學約束。
星系並非無偏地描繪暗物質。在大尺度的線性偏置近似下 $\delta_g = b\,\delta_m$,而高峰偏置(peak-background split)指出,越大質量的暈、$b$ 越大——這是因為大暈傾向誕生在大尺度過密的背景上。理解偏置是把 $\xi_{\text{galaxy}}$ 翻譯回 $\xi_{\text{matter}}$、進而做精密宇宙學的必經關卡,也是當前 EFTofLSS(大尺度結構有效場論)等理論框架著力處理的核心。
高階統計與場層級推論:超越兩點函數
兩點函數只能完整描述高斯隨機場。但重力的非線性演化會把初始接近高斯的場揉出非高斯性——纖維、空洞這種帶相位關聯的結構,資訊大量藏在三點、四點等高階矩中。三點相關函數及其傅立葉對偶雙譜(bispectrum) $B(k_1, k_2, k_3)$ 因此攜帶了 $P(k)$ 看不到的訊息:它能同時打破成長率 $f$、偏置 $b$ 與 $\sigma_8$ 之間的簡併,也是搜尋原初非高斯性(primordial non-Gaussianity,$f_{\text{NL}}$)——暴脹不同模型的關鍵判據——的主戰場。
更前沿的方向是場層級推論(field-level inference) 與機器學習:不再把場壓縮成 $\xi$ 或 $P(k)$ 這類摘要統計(必然丟失資訊),而是直接對整個觀測密度場、結合可微分的前向模擬(differentiable forward model)做貝氏推論,原則上榨取每一比特的宇宙學資訊。配合 DESI、Euclid、Vera Rubin 天文台(LSST) 與 SKA 等將測繪數十億星系與中性氫的計畫,大尺度結構正從「驗證 $\Lambda$CDM」邁向「以前所未有的精度逼問暗能量本質、重力是否正確、以及暴脹留下的原初印記」。從一張看似亂糟糟的星系地圖,到這些直指宇宙根本問題的數字,靠的始終是同一件事:把隨機,當成最嚴謹的物理來讀。